คู่มือเจาะลึก: พื้นฐานภาษา C++ และการจัดการหน่วยความจำสำหรับงานสมองกลฝังตัว

ทำความเข้าใจการจัดการหน่วยความจำ C++ สำหรับระบบฝังตัว
ในฐานะ Software Architect หรือวิศวกรระบบสมองกลฝังตัว การเข้าใจเพียงแค่ “ไวยากรณ์” (Syntax) ของภาษา C++ นั้นไม่เพียงพอแน่นอนครับ แต่คุณต้องเข้าใจถึง “กลไกเบื้องหลัง” อย่างถ่องแท้ โดยเฉพาะเรื่องของการจัดการหน่วยความจำและโครงสร้างข้อมูล ไม่ว่าคุณจะทำ Edge Machine Learning บน ESP32, ทำงานกับระบบ Concurrency บน FreeRTOS หรือรันอัลกอริทึมทางเรขาคณิตที่ซับซ้อน ทั้งหมดนี้ต้องการระบบที่มีประสิทธิภาพสูงและปลอดภัย
คู่มือฉบับนี้เราจะสรุปหลักการสำคัญ โดยอิงภาพการทำงานจริงจากการพัฒนาระบบระดับโปรให้เห็นภาพกันครับ
1. โครงสร้างพื้นฐานของโปรแกรม C++ (C++ Program Structure)
โปรแกรม C++ ที่ดีและสเกลได้เริ่มต้นจากการวางโครงสร้างที่ชัดเจน ประกอบด้วยการดึง Library ที่จำเป็น (Headers), การนิยามโครงสร้างข้อมูล (Data Structures) และจุดเริ่มต้นการทำงาน (Entry Point)
- การใช้
#include: สำหรับดึงความสามารถจาก Library เจ๋งๆ เช่น<atomic>และ<thread>สำหรับงาน Concurrency หรือ<nlohmann/json.hpp>สำหรับการจัดการข้อมูล JSON ตอนทำเดต้า Machine Learning - ฟังก์ชัน
main(): คือจุดเริ่มต้นของโปรแกรม (Entry Point) พอมาเป็นโลกของ RTOS มันอาจจะอยู่ในรูปของapp_main()หรือ Task เริ่มต้นที่เป็นแกนหลัก - การกำหนดขอบเขต (Scope): เครื่องหมายปีกกา
{ }ไม่ได้มีไว้แค่จัดกลุ่มโค้ดให้ดูสวยงาม แต่มันคือตัวกำหนด “วงจรชีวิต” ของตัวแปร และใช้เครื่องหมาย Semicolon;เพื่อจบคำสั่งเสมอเมื่อสั่งงานเสร็จ
ตัวอย่างการวางโครงสร้าง:
#include <iostream>
#include <atomic>
#include <nlohmann/json.hpp> // จำเป็นมากสำหรับงาน ML
// นิยาม Struct สำหรับข้อมูล Point งาน Geometry
struct Point {
double x, y;
};
int main() {
// สร้าง Object เอาไว้แค่บน Stack
Point p{10.5, 20.0};
{
// ขอบเขตภายใน (Inner Scope) กระพริบตาเดียวก็หายไป
std::atomic<int> counter(0);
counter.store(1, std::memory_order_relaxed);
} // counter จะถูกลบทำลายทิ้งอัตโนมัติที่บรรทัดนี้ทันที (Stack Unwinding)
return 0;
}
2. ตัวแปรและประเภทข้อมูล (Variables and Data Types)
การเลือก Data Type ให้เหมาะสมมีผลโดยตรงต่อ Memory และความแม่นยำของอัลกอริทึม ยิ่งในโลกของชิปที่มีแรมจำกัด การเลือกใช้ Type ผิด ชีวิตเปลี่ยนได้เลย!
| ประเภทข้อมูล (Data Type) | คำอธิบาย (Description) |
|---|---|
int |
เลขจำนวนเต็มมาตรฐาน ใช้ทั่วไป นับลูป หรือเอาไว้อ้างอิง Array Index |
uint32_t |
เลขจำนวนเต็มบวก 32 บิต เหมาะมากสำหรับเก็บ ID, จัดการ Hardware Register หรือการนับ Byte แบบเป๊ะๆ ไม่ติดลบ |
double |
เลขทศนิยมความละเอียดสูง (ใช้สำหรับพิกัด x, y ใน Point หรือ Vector) ข้อควรระวัง: บน Microcontroller ทั่วไปอาจเลือกใช้ float แทนถ้าฮาร์ดแวร์ไม่มี Double-precision FPU แบบ Native เพื่อรีด Performance ให้ออกมาสูงสุด |
bool |
ค่าทางตรรกศาสตร์ (เช่น ใช้เช็คสถานะ Flag ใน HandlerState) |
std::string |
ชุดข้อความแบบยืดหยุ่น ถ้าใช้ในชิปที่แรมจำกัดมากๆ อย่าง STM32 ตัวเล็กๆ ต้องระวังเพราะอาจทำให้เกิด Heap Fragmentation ได้ เลี่ยงได้ก็เอา char array มาใช้ |
struct / class |
การสร้าง Type รูปแบบใหม่ (User-defined types) ให้เป็น Blueprint ของชุดข้อมูลในระบบเรา |
3. การจัดการหน่วยความจำ: Stack vs. Heap (Memory Management Concepts)
ในระดับสถาปัตยกรรมระบบ การตัดสินใจว่าจะวางข้อมูลเอาไว้ที่ส่วนไหน ส่งผลต่อความเร็ว Performance โดยตรงและโคตรจะมหาศาลครับ
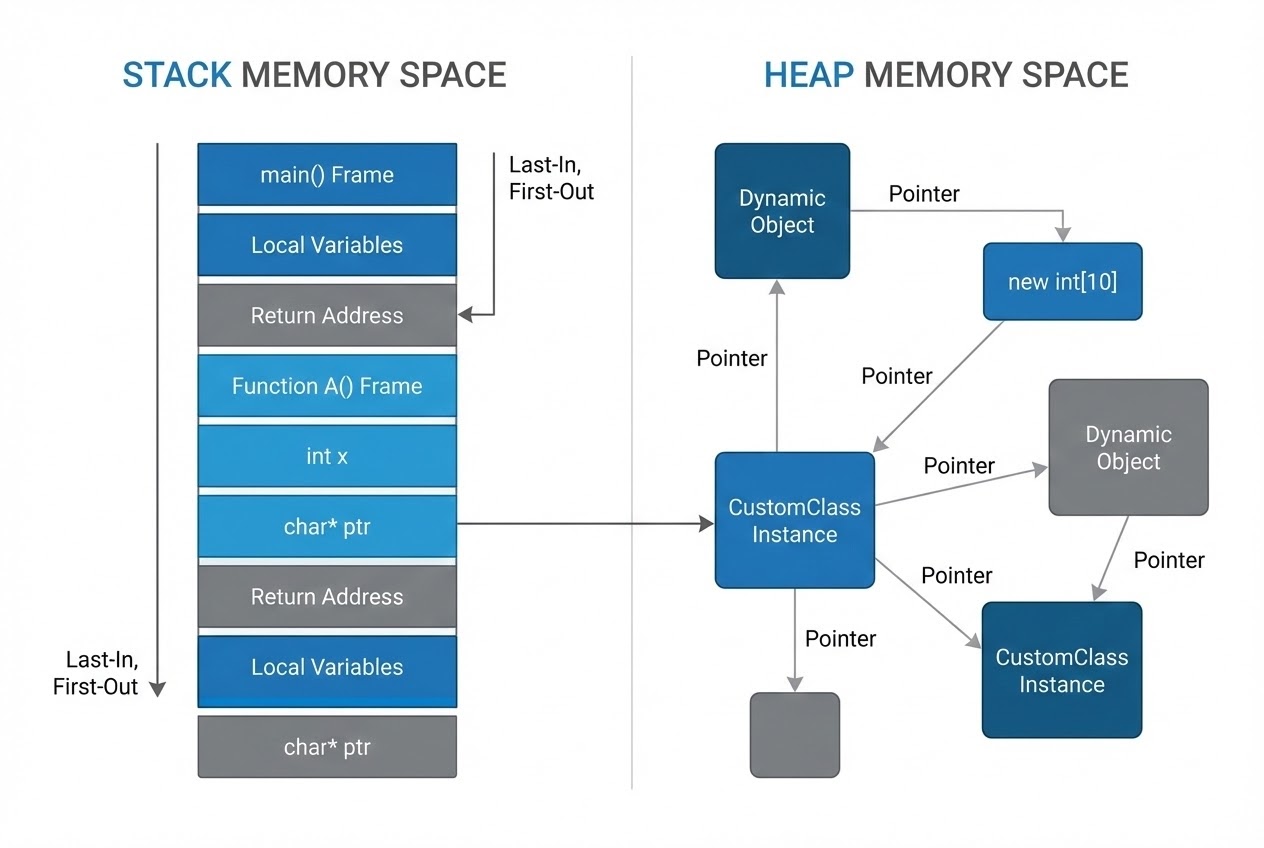
- Stack (Automatic Storage):
- ใช้เก็บตัวแปรแบบ Local เช่น ตัวแปรที่ประกาศสั้นๆ ในฟังก์ชันการคำนวณที่ทำงานแป๊บเดียวเสร็จ
- ข้อดี: ทำงานเร็วปรู๊ดปร๊าด (แบบ LIFO) และถูกเคลียร์แรมทิ้งเองเมื่อสิ้นสุด Scope ทันที
- ข้อระวัง: พื้นที่มีจำกัดมาก (ยิ่งใน ESP32 ที่ต้องกำหนดขนาด Task Stack ห้ามล้น) และข้อมูลจะหายไปทันทีเมื่อจบฟังก์ชัน ถ้าจะ return ค่าเป็น Pointer ระวังชี้มั่ว
- Heap (Dynamic Storage):
- เวลาจะใช้ต้องจองพื้นที่ผ่านคำสั่ง
new(เช่นX* x = new X;หรือการแตก Node ใหม่ในโครงสร้าง Linked แบบ Lock-free) - ข้อดี: พื้นที่ใหญ่โต ข้อมูลคงอยู่ได้ยาวนานตลอดโปรแกรมถ้าเราไม่สั่งลบ เหมาะสำหรับ Object บักเอ้ก ก้อน Buffer ใหญ่ๆ หรืองาน Linked Structures สายจัดระเบียบ
- ข้อระวัง: ถ้าจองแล้วลืมลบ มันจะนำไปสู่ปัญหาลืมพอยน์เตอร์ (Dangling Pointer) อาการ Memory Leaks และปัญหา Fragmentation บานเบอะที่ทำโปรแกรมแฮงค์ค้างไปได้เลย
- เวลาจะใช้ต้องจองพื้นที่ผ่านคำสั่ง
4. ตัวชี้ (Pointers) และการอ้างอิง (References)
สองตัวนี้คือกลไกไม้ตายที่ C++ เตรียมไว้ให้เราเข้าไปคุม Address ของข้อมูล Memory ได้โดยตรงระดับลึก
- Pointer (
*): ตัวแปรที่ใช้เก็บเลขที่อยู่ (Address) เช่นX* pคือชี้เป้าไปที่ Object typeXที่ลอยเคว้งอยู่บน Heap - Reference (
&): การสร้างชื่อนามแฝง (Alias) ให้กับตัวแปรที่มีอยู่เดิมแล้ว นิยมใช้เช่น ตอนใช้std::ref(data)กระโดดส่งค่าไปให้ Thread อื่นประมวลผลต่อใน FreeRTOS แบบ Concurrent ลดภาระการ Copy ข้อมูลใหญ่ๆ ไม่ให้ RAM กระตุก
[WARNING] Dangling Pointers & Race Conditions: จำไว้ตัวโตๆ ว่าในบทเรียนเรื่อง Lock-free Data Structures ปัญหาปวดตับที่พบบ่อยสุดคือ Thread ที่ 1 กำลังลบทำลาย Node ทิ้ง (Delete) แต่ดันมี Thread ที่ 2 พยายามจะแงะอ่านค่าจาก Pointer ตัวเดียวกันนั้นอยู่! การจัดการวงจรชีวิตของ Pointer ในโลกของ Concurrent จึงซับซ้อนและต้องใจเย็นสุดๆ
5. การจัดการหน่วยความจำแบบ Manual ด้วย New และ Delete
ถ้าคุณกระโดดเข้าไปเล่นกับ Heap แปลว่าคุณต้องรับผิดชอบชีวิตของ Object สไตล์ร้อยเปอร์เซ็นต์เต็ม:
- Allocation: ใช้
newเพื่อยื่นขอพื้นที่แรมและสั่งรัน Constructor ให้เริ่มต้นชุดข้อมูล - Utilization: เอาข้อมูลมาถล่มใช้งานผ่าน Pointer อย่างเมามัน
- Deallocation: รันเสร็จปุ๊บ คุณต้องใช้คำสั่ง
deleteเพื่อกวาดล้างและคืนหน่วยความจำให้ระบบเสมอ ถ้าลืม = ซิ่งลืมเบรก Memory Leak ชัวร์
ความท้าทายหน้างานจริง: ลองคิดภาพการออกแบบระบบแบบ Lock-free การลบ Node ทิ้งทันทีหลังจากการ Pop ข้อมูลออก อาจทำให้โปรแกรมระเบิดเป็นผุยผง (Dangling Pointer) ทีมพัฒนาเก๋าๆ เลยมักต้องใช้เทคนิคขั้นสูงอย่าง Hazard Pointers หรือเล่นท่า Reference Counting เพื่อให้มั่นใจชัวร์ๆ ว่าไม่มี Process หรือ Task ไหนกำลังเล็ง Pointer นั้นอยู่ ก่อนจะสั่ง delete ปิดจ็อบแบบเบ็ดเสร็จเรียบร้อย
6. บทนำสู่ Smart Pointers
เพื่อหยุดยั้งปัญหา Human Error อย่างการลืม delete จนระบบพัง ภาษา Modern C++ ตัวใหม่ๆ เบยผลักดัน “Ownership Model” ให้นักพัฒนาเปลี่ยนมาใช้งาน Smart Pointers แทน ซึ่งใช้หลักการ RAII (Resource Acquisition Is Initialization) มาช่วยกวาดขยะคืนหน่วยความจำให้แบบอัตโนมัติ
std::unique_ptr(Exclusive Ownership):- โชว์ความเก๋าว่าข้าคือเจ้าของ Resource นี้เพียงผู้เดียวไม่มีใครแย่งได้
- เมื่อตัวมันเองหลุด Scope ไป (ทำงานจบ) มันจะทำการสั่ง
deleteของข้างในทิ้งให้โดยอัตโนมัติแบบไร้ร่องรอย นิยมมากๆ ในงานแบบfunction_wrapperหรือจัดการ Node ภายในthreadsafe_queue
std::shared_ptr(Shared Ownership):- ใช้ระบบนับจำนวน (Reference Counting) เพื่อดูว่ามีคนถือ Resource ก้อนนี้ร่วมกันอยู่กี่คน ตอนนี้อยู่ไหนบ้าง
- Resource จริงๆ จะถูกเตะปลั๊กทำลายก็ต่อเมื่อคนที่ถือครองตัวสุดท้ายสั่งคืนพื้นที่พ้นสภาพ (Reference count เหลือ 0 เป๊ะ)
[NOTE] Technical Warning: ถึงแม้
std::shared_ptrจะมากับความปลอดภัยระดับสูงลิ่ว แต่ในงานที่ต้องการความเร็ว Performance สูงสุดๆ (เช่น Lock-free Interrupt ภายในวินาทีเฉียดเสี้ยว) คุณต้องระวังไว้ด้วยว่ามันอาจไม่ได้ทำงานแบบ Lock-free ในบาง Platform ของ Compiler เสมอไป และยังมี Overhead แฝงยิบย่อยจากการมัวแต่นับ Reference Count ซึ่งในจุดนี้สถาปนิกซอฟต์แวร์ต้องเป็นคนประเมินชั่งน้ำหนักข้อดีข้อเสียให้ดีครับว่าคุ้มหรือเปล่า
สรุป (Conclusion)
การเข้าใจเรื่อง Memory Management ของภาษา C++ จะช่วยอัปเลเวลยกระดับคุณจากแค่คนเขียนโค้ด ให้กลายเป็นวิศวกรออกแบบระบบเต็มตัว ไม่ว่าคุณจะลุยงาน Edge AI, ดัน Performance ของ Web Server ที่มี Concurrency มหาศาลบี้กับ NodeMCU หรือคำนวณ Matrix ที่ซับซ้อน การตีโจทย์ให้แตกว่าควรใช้ Stack, Heap, Pointer อย่างไร และจัดการ Lifecycle ให้เป็นระเบียบเรียบร้อย คือกุญแจสำคัญสู่การทำโค้ดที่รันได้ยาวๆ ฮาร์ดแวร์ทำงานได้ไม่เพี้ยนนั่นเองครับ
บรรณานุกรมและการศึกษาเพิ่มเติม (References)
- Anthony Williams - C++ Concurrency in Action
- Kirill Kolodiazhnyi - Hands-On Machine Learning with C++
- Daniel Sunday PhD - Practical Geometry Algorithms with C++ Code