Preprocessing: แกะรอยด่านแรกของ Translation Process หุ่นยนต์พิมพ์ดีดเบื้องหลังการคอมไพล์ C

บทนำ (Introduction)
สวัสดีครับน้องๆ วิศวกรและเพื่อนนักพัฒนาชาว www.123microcontroller.com ทุกคน! กลับมาพบกับวิศวกรขอบตาดำๆ กันอีกครั้งครับ วันนี้เราจะมาขยายมุมมองให้กว้างขึ้น เพื่อทำความเข้าใจสิ่งที่เกิดขึ้น “เบื้องหลัง” ทันทีที่เรากดปุ่ม Build หรือรันคำสั่งคอมไพล์โปรแกรมครับ
หลายคนอาจจะคิดว่าซอร์สโค้ดภาษา C ของเราถูกส่งตรงเข้า Compiler เพื่อแปลงเป็นภาษาเครื่องเลยทันที แต่ในความเป็นจริงแล้ว มาตรฐานภาษา C ได้กำหนดกระบวนการทำงานที่เรียกว่า Translation Process (กระบวนการแปลภาษา) ซึ่งแบ่งออกเป็นหลายขั้นตอนย่อยๆ และ “ด่านแรก” ที่สำคัญที่สุดที่โค้ดของเราต้องเผชิญก็คือ Preprocessing (การประมวลผลล่วงหน้า) ครับ วันนี้เราจะมาเจาะลึกกันว่า แหล่งข้อมูลชั้นครูอธิบายบทบาทของ Preprocessing ในบริบทที่กว้างขึ้นของ Translation Process ไว้อย่างไรบ้าง ไปลุยกันเลยครับ!
เนื้อหาหลัก (Core Concept): กระบวนการ Translation Process และบทบาทของ Preprocessor
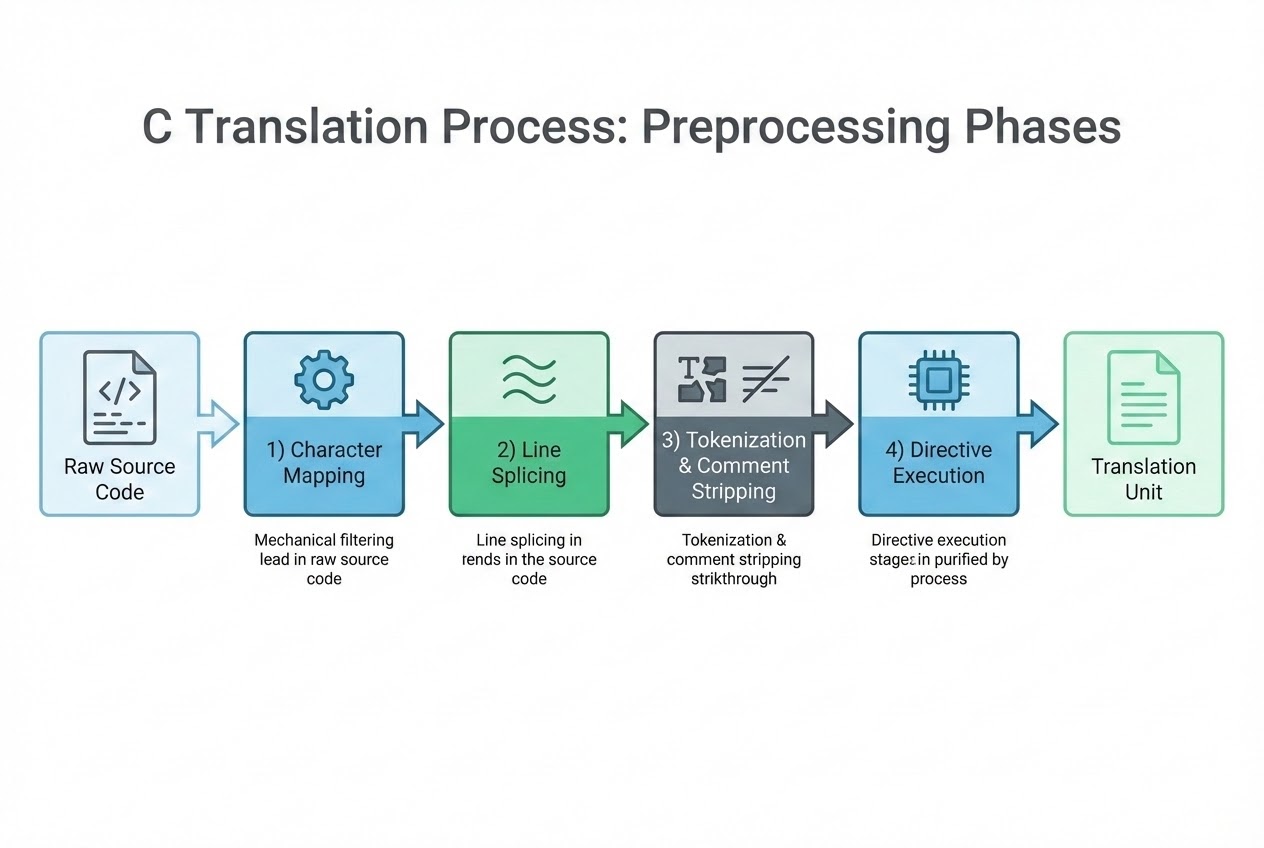
ในบริบทของการแปลภาษา (Translation Process) แหล่งข้อมูลระบุไว้อย่างชัดเจนว่า กระบวนการนี้ประกอบไปด้วย 8 ขั้นตอน (Phases) ต่อเนื่องกัน โดย Preprocessing จะครอบคลุมกระบวนการใน 4 ขั้นตอนแรกสุด ก่อนที่โค้ดจะถูกส่งต่อไปยังตัว Compiler จริงๆ (ในขั้นตอนที่ 7)
ลองจินตนาการว่า Preprocessor เป็น “หุ่นยนต์บรรณาธิการ (Specialized Text Editor)” ที่ทำหน้าที่จัดเตรียมและแก้ไขข้อความในไฟล์โค้ดตามคำสั่งของเรา ก่อนจะส่งต้นฉบับที่สะอาดเอี่ยมไปให้ช่างก่อสร้าง (Compiler) ครับ โดยหุ่นยนต์ตัวนี้จะทำงานตามลำดับ 4 ขั้นตอน (Phases 1-4) ดังนี้:
- Phase 1: Character Mapping (การจับคู่ตัวอักษร): ซอร์สโค้ดที่เราพิมพ์จะถูกแปลงให้อยู่ในรูปแบบชุดตัวอักษรมาตรฐานที่ระบบเข้าใจ (Source file character mapping) ในอดีตขั้นตอนนี้จะทำการแปลงชุดตัวอักษรพิเศษที่เรียกว่า Trigraphs ให้เป็นอักขระปกติด้วย (เช่น แปลง
??=เป็น#) - Phase 2: Line Splicing (การเชื่อมบรรทัด): หากเราเขียนโค้ดยาวๆ แล้วใช้เครื่องหมาย Backslash (
\) ตามด้วยการขึ้นบรรทัดใหม่ (Newline) Preprocessor จะทำการ “ลบ” ทั้งตัว\และ Newline ทิ้ง เพื่อเชื่อมโค้ดให้กลับมาเป็นบรรทัดเดียวกันทางลอจิก - Phase 3: Tokenization และ Comment Stripping (การหั่นคำและลบคอมเมนต์): โค้ดจะถูกสับเป็นชิ้นเล็กๆ ที่มีความหมายเรียกว่า “Tokens” (เช่น ชื่อตัวแปร, เครื่องหมาย) ที่สำคัญในขั้นตอนนี้คือ คอมเมนต์ทั้งหมด (
/* ... */หรือ//) จะถูกลบทิ้ง และแทนที่ด้วยช่องว่าง (Space) เพียง 1 เคาะ - Phase 4: Directive Execution (การประมวลผลคำสั่ง #): นี่คือหัวใจหลักครับ! Preprocessor จะมองหาคำสั่งที่ขึ้นต้นด้วย
#(เช่น#include,#define,#ifdef) แล้วทำการดึงไฟล์อื่นมาแทรก, ทำการแทนที่ Macro (Macro expansion), หรือเลือกลบโค้ดทิ้งตามเงื่อนไข (Conditional compilation) หลังจากทำตามคำสั่งเสร็จแล้ว บรรทัดที่มี#เหล่านี้จะถูกลบทิ้งไปทั้งหมด
ผลลัพธ์ที่ได้คืออะไร?
เมื่อจบ Phase 4 เราจะได้สิ่งที่เรียกว่า “Translation Unit” (มักจะใช้นามสกุลไฟล์ .i) ซึ่งเป็นซอร์สโค้ดภาษา C ล้วนๆ ที่ไม่มีคอมเมนต์ ไม่มีคำสั่ง # หลงเหลืออยู่เลย และมีการแทนที่ Macro ทั้งหมดแล้ว ไฟล์ Translation Unit นี้นี่แหละครับที่จะถูกส่งต่อไปให้ Compiler ทำการวิเคราะห์ไวยากรณ์ (Syntax analysis) และแปลเป็นภาษาเครื่องต่อไป
ตัวอย่างโค้ด (Code Example): จาก Source Code สู่ Translation Unit
มาดูกันครับว่า หุ่นยนต์ Preprocessor เปลี่ยนแปลงหน้าตาโค้ดของเราอย่างไรผ่าน 4 ขั้นตอนแรกของ Translation Process
โค้ดต้นฉบับ (main.c ก่อนทำ Preprocessing):
#include "my_hardware.h" /* 1. แทรกไฟล์ (Phase 4) */
/* 2. สร้าง Macro พร้อมการต่อบรรทัด (Phase 2 & 4) */
#define SETUP_LED() \
PORTB |= 0x01; \
DDRB |= 0x01;
int main(void) {
// 3. คอมเมนต์นี้จะถูกลบทิ้ง (Phase 3)
int a = 10;
SETUP_LED(); /* 4. ตรงนี้จะถูกกระจายร่าง (Phase 4) */
return 0;
}
ผลลัพธ์ที่ได้ (Translation Unit ที่ถูกส่งให้ Compiler ใน Phase 7):
extern void hw_init(void); /* สมมติว่านี่คือเนื้อหาที่ถูกดึงมาจาก my_hardware.h */
int main(void) {
int a = 10;
PORTB |= 0x01; DDRB |= 0x01;;
return 0;
}
สังเกตว่า: คอมเมนต์หายไป, คำสั่ง # หายไป, และ SETUP_LED() ถูกแทนที่เป็นโค้ด C ปกติเรียบร้อยแล้ว นี่คือสิ่งที่ Compiler มองเห็นครับ!
ข้อควรระวัง / Best Practices
การทำความเข้าใจว่า Preprocessing เป็นเพียง “การแทนที่ข้อความ (Textual substitution)” ที่เกิดขึ้น “ก่อน” การคอมไพล์ (Compiler) จะช่วยให้เราหลีกเลี่ยงบั๊กสยองขวัญได้ครับ แหล่งข้อมูลระดับ Expert และมาตรฐาน Secure Coding (CERT C) ได้เตือนไว้ดังนี้:
- Preprocessor ไม่รู้จักไวยากรณ์ของ C (Lack of Semantic Knowledge): หุ่นยนต์ Preprocessor ไม่รู้จักเรื่อง Types (ชนิดข้อมูล), ตัวแปร, ฟังก์ชัน หรือ Scope ใดๆ ทั้งสิ้น มันทำงานระดับ Text เท่านั้น หากคุณเขียน Macro ผิดหลักไวยากรณ์ Preprocessor จะยอมผ่านให้ แต่ Compiler ใน Phase 7 จะพ่น Error ออกมา ซึ่งบ่อยครั้งจะชี้ไปที่บรรทัดที่เรียกใช้ Macro ทำให้การ Debug หาต้นตอปัญหาทำได้ยากมาก
- ระวัง Side Effects ใน Macro Arguments (กฎ PRE31-C): เมื่อมีการส่งตัวแปรเข้าไปใน Macro เช่น
MACRO(x++)เนื่องจากมันเป็นการก๊อปปี้ข้อความไปวาง หากใน Macro มีการอ้างถึงxหลายครั้ง (เช่น การหาค่า Max/Min) ตัวแปรxจะถูกสั่ง++ซ้ำหลายรอบ (Multiple evaluations) ทำให้พฤติกรรมของโปรแกรมผิดเพี้ยนแบบหาจับมือใครดมไม่ได้! (Undefined behavior) แนะนำให้ใช้ Inline function แทนใน C ยุคใหม่ - ปัญหา Token Pasting (
##): การใช้คำสั่ง##ใน Phase 4 เพื่อนำ Token สองตัวมาต่อกัน (Token concatenation) ผลลัพธ์ที่ได้หลังจากการต่อ จะต้องเป็น Token ที่ถูกต้องตามกฎของภาษา C เท่านั้น (เช่น สร้างชื่อตัวแปรใหม่ที่ถูกต้อง) หากต่อกันแล้วเกิดเป็น Token ประหลาด จะถือว่าเป็น Undefined Behavior (ตามกฎ PRE32-C)
สรุป (Conclusion)
ในภาพรวมของกระบวนการ Translation Process นั้น ขั้นตอน Preprocessing คือแนวหน้าด่านแรกที่ทำหน้าที่แปรสภาพซอร์สโค้ดดิบๆ จัดการรวบรวมไฟล์ ลบคอมเมนต์ และกระจายร่าง Macro เพื่อสร้าง Translation Unit ที่บริสุทธิ์ให้กับ Compiler ครับ การเข้าใจลำดับชั้นนี้ จะช่วยให้วิศวกร Embedded อย่างเราสามารถใช้ประโยชน์จาก #define และ #ifdef ในการควบคุมการคอมไพล์สำหรับฮาร์ดแวร์หลายๆ รุ่นได้อย่างแม่นยำและปลอดภัยครับ!
หากเพื่อนๆ สนใจอยากดูวิธีการใช้คำสั่งแปลกๆ ในช่วง Preprocessing เช่น การใช้ #pragma ควบคุม Compiler ของบอร์ดแต่ละค่าย หรืออยากแชร์ประสบการณ์บั๊กหลอนๆ จาก Macro แวะเข้ามาตั้งกระทู้คุยกันต่อที่เว็บบอร์ด www.123microcontroller.com ของพวกเราได้เลยนะครับ แล้วพบกันใหม่บทความหน้า Happy Coding ครับทุกคน!