Loop Unrolling: ฉีกกฎลูปวนซ้ำ รีดความเร็วขั้นสุดด้วยศิลปะการ "คลี่โค้ด"

บทนำ (Introduction)
สวัสดีครับน้องๆ วิศวกรและเพื่อนนักพัฒนาชาว www.123microcontroller.com ทุกคน! กลับมาพบกับวิศวกรขอบตาดำๆ กันอีกครั้งครับ วันนี้เราจะมาคุยกันถึงเทคนิคการทำ Optimization (การรีดประสิทธิภาพ) ระดับตำนานที่ชื่อว่า Loop Unrolling (การคลี่ลูป) ครับ
เวลาที่เราเขียนโปรแกรม C เราทุกคนคุ้นเคยกับการใช้ลูปอย่าง for หรือ while เพื่อทำคำสั่งซ้ำๆ ใช่ไหมครับ? แต่ในโลกของฮาร์ดแวร์ การวนลูปมี “ค่าใช้จ่ายแอบแฝง” เสมอ ลองจินตนาการว่าน้องๆ กำลังแพ็คของใส่กล่อง 100 กล่อง ถ้าแพ็ค 1 กล่องแล้วต้องหันไปขีดเช็คลิสต์ 1 ที (เช็คเงื่อนไขลูป) กว่าจะครบ 100 กล่องคงเสียเวลาหันไปหันมาน่าดู แต่ถ้าเราเปลี่ยนเป็นแพ็คทีละ 4 กล่อง แล้วค่อยหันไปขีดเช็คลิสต์ 1 ทีล่ะ? งานก็จะเสร็จไวขึ้นมาก! นี่แหละครับคือคอนเซปต์ของ Loop Unrolling ในมุมมองของนักพัฒนาและคอมไพเลอร์ วันนี้เราจะมาแงะตำราดูกันว่า แหล่งข้อมูลระดับเซียนอธิบายเรื่องนี้ในบริบทที่กว้างขึ้นของ Optimization ไว้อย่างไรบ้าง ไปลุยกันเลยครับ!
เนื้อหาหลัก (Core Concept): กลไกและพลังของ Loop Unrolling
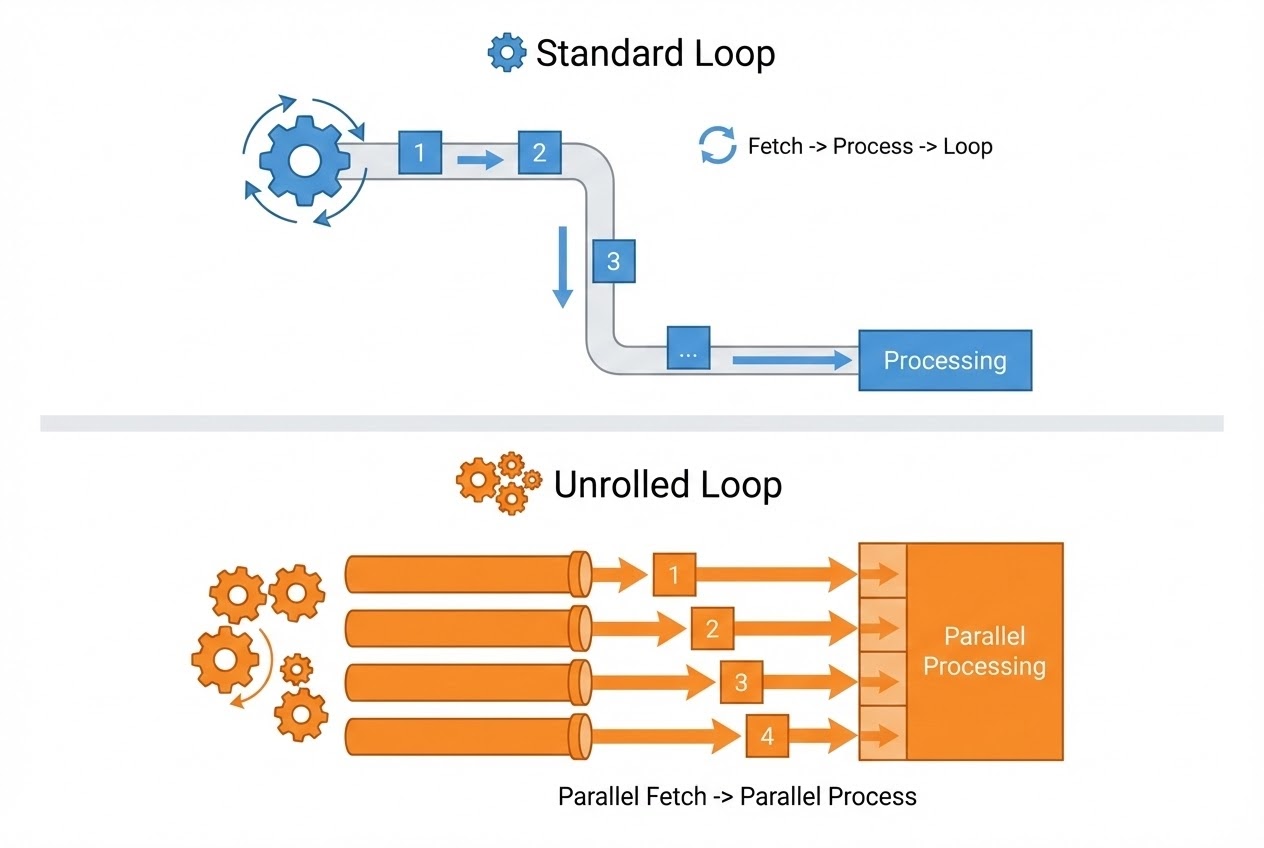
ในบริบทที่กว้างขึ้นของการทำ Optimization ระดับ Compiler (Compiler Optimization) นั้น Loop Unrolling คือเทคนิคการแปลงโครงสร้างลูป เพื่อลดความสูญเปล่าจากการควบคุมลูป (Loop Control Overhead) และรีดประสิทธิภาพของ CPU ให้ถึงขีดสุด โดยมีหลักการทำงานและผลกระทบดังนี้ครับ:
- 1. การกำจัด Loop Overhead: ทุกครั้งที่ลูปทำงานครบ 1 รอบ (Iteration) CPU จะต้องทำ 3 สิ่งคือ: 1) บวกค่าตัวแปรนับรอบ (Increment) 2) ตรวจสอบเงื่อนไข (Condition Evaluation) และ 3) กระโดดกลับไปเริ่มลูปใหม่ (Branch Instruction) การทำ Loop Unrolling จะ “ก๊อปปี้” คำสั่งในลูปมาวางต่อๆ กันหลายๆ ชุดใน 1 รอบ เพื่อให้ CPU ทำงานหลักได้มากขึ้น และเสียเวลาเช็คเงื่อนไขหรือกระโดดน้อยลง
- 2. เพิ่ม Instruction-Level Parallelism (ILP): นอกจากจะลด Overhead แล้ว การคลี่ลูปยังช่วยเปิดโอกาสให้ CPU สมัยใหม่ที่มีสถาปัตยกรรมแบบ Pipeline หรือ Superscalar สามารถนำคำสั่งหลายๆ คำสั่งที่ไม่มีความเกี่ยวข้องกัน (Independent instructions) ไปประมวลผลพร้อมๆ กันในระดับฮาร์ดแวร์ได้ (Instruction-Level Parallelism)
- 3. ลดปัญหา Branch Misprediction: การกระโดด (Branch) เป็นของแสลงสำหรับ CPU Pipeline ครับ เพราะถ้า CPU เดาทางกระโดดผิด มันจะต้องล้างท่อใหม่หมด (Pipeline Flush) การลดจำนวนครั้งที่ต้องเช็คลูป จึงช่วยลดความเสี่ยงของ Branch Misprediction penalties ได้โดยตรง
- 4. การจับคู่กับ Vectorization (SIMD): บ่อยครั้งที่ Compiler ใช้ Loop Unrolling เป็นทางผ่านไปสู่การทำ Vectorization (เช่น การใช้ชุดคำสั่ง SSE/AVX หรือคำสั่งแบบประมวลผลข้อมูลชุดใหญ่ในคลิกเดียว) ทำให้สามารถดึงข้อมูลหลายๆ ไบต์จาก Array มาบวกหรือคูณพร้อมกันได้เลย
- 5. Time-Space Trade-off (แลกพื้นที่กับความเร็ว): เหรียญมีสองด้านเสมอครับ! การคลี่ลูปด้วยการก๊อปปี้โค้ด ย่อมแลกมาด้วย “ขนาดของโปรแกรมที่ใหญ่ขึ้น (Code Bloat)” ในระบบ Embedded ที่มี Flash Memory จำกัด เราต้องชั่งน้ำหนักให้ดีว่าความเร็วที่ได้มา คุ้มกับพื้นที่ ROM ที่เสียไปหรือไม่
ตัวอย่างโค้ด (Code Example):
มาดูตัวอย่างการคลี่ลูปด้วยมือแบบง่ายๆ สมมติว่าเราต้องการคัดลอกข้อมูลเซ็นเซอร์จาก Array หนึ่งไปยังอีก Array หนึ่ง หากเรารู้ว่าจำนวนข้อมูลเป็นผลคูณของ 4 แน่ๆ เราสามารถเขียน C ให้ทำงานเร็วขึ้นได้แบบนี้ครับ:
#include <stdint.h>
#define DATA_SIZE 100
/*
* วิธีที่ 1: ลูปปกติ (Normal Loop)
* CPU ต้องทำการเช็ค i < DATA_SIZE และ i++ ถึง 100 ครั้ง!
*/
void copy_data_normal(uint32_t *dest, const uint32_t *src) {
for (uint32_t i = 0; i < DATA_SIZE; ++i) {
dest[i] = src[i];
}
}
/*
* วิธีที่ 2: Loop Unrolling (คลี่ลูปทีละ 4 คำสั่ง)
* CPU จะทำการเช็คเงื่อนไขและ i += 4 เพียงแค่ 25 ครั้งเท่านั้น!
* ลด Overhead ลงไปได้ถึง 75%
*/
void copy_data_unrolled(uint32_t *dest, const uint32_t *src) {
/* สมมติว่าเรารู้แน่ๆ ว่า DATA_SIZE เป็นผลคูณของ 4 */
for (uint32_t i = 0; i < DATA_SIZE; i += 4) {
dest[i] = src[i];
dest[i + 1] = src[i + 1];
dest[i + 2] = src[i + 2];
dest[i + 3] = src[i + 3];
}
}
ข้อควรระวัง / Best Practices:
แม้ Loop Unrolling จะดูทรงพลัง แต่บรรดาคัมภีร์วิศวกรรมซอฟต์แวร์และการปรับแต่งประสิทธิภาพ ได้เตือนถึงหลุมพรางสำคัญไว้ดังนี้ครับ:
- จงปล่อยให้ Compiler ทำให้ (Trust the Compiler): ในยุคปัจจุบัน Compiler อย่าง GCC ฉลาดมากครับ มันสามารถคลี่ลูปให้เราอัตโนมัติหากเราเปิด Flag Optimization (เช่น
-O2,-O3หรือ-funroll-loops) การไปฝืนเขียนโค้ดคลี่ลูปด้วยมือ (Manual unrolling) อาจทำให้โค้ดอ่านยาก (Unreadable) และบ่อยครั้ง Compiler ทำได้ดีกว่าเราครับ ยกเว้นแต่ว่าเรามี “ความรู้เฉพาะเจาะจงของฮาร์ดแวร์” ที่ Compiler ไม่รู้ - ระวังโค้ดบวมจนล้น Cache (Instruction Cache Miss): หากคุณคลี่ลูปที่มีขนาดใหญ่อยู่แล้วให้ใหญ่ขึ้นไปอีก จนขนาดของมันใหญ่เกินกว่า Instruction Cache ของ CPU มันจะทำให้ CPU ต้องเสียเวลาไปโหลดโค้ดจาก Memory หลักเข้ามาใหม่ตลอดเวลา (Cache thrashing) ซึ่งจะทำให้โปรแกรมทำงาน “ช้าลง” กว่าลูปปกติเสียอีกครับ!
- ปัญหาเรื่องขนาดที่ไม่ลงตัว: ในชีวิตจริง ขนาดของข้อมูลในลูปอาจไม่ได้หาร 4 หรือหาร 8 ลงตัวเสมอไป (เช่น มีข้อมูล 103 ตัว) ทำให้ในการทำ Manual Unrolling คุณจะต้องเขียนโค้ดพิเศษไว้หลังลูป เพื่อจัดการกับ “เศษข้อมูล (Remainder)” ที่เหลืออยู่ ซึ่งเพิ่มความซับซ้อนและโอกาสเกิดบั๊ก (เช่น Array Out of Bounds)
- Duff’s Device: ในอดีตมีทริคการเขียน C ระดับฮาร์ดคอร์ที่เรียกว่า “Duff’s Device” ซึ่งใช้คำสั่ง
switchคร่อมทับเข้าไปในลูปwhileเพื่อทำ Loop Unrolling และจัดการกับเศษที่ไม่ลงตัวไปพร้อมๆ กัน แม้จะฉลาดมาก แต่มันทำให้โค้ดเป็นลักษณะ Obfuscated (อ่านยากและซับซ้อน) ผู้เชี่ยวชาญแนะนำว่าให้หลีกเลี่ยงการใช้ท่านี้แล้วปล่อยเป็นหน้าที่ของ Compiler ดีกว่าครับ
สรุป (Conclusion)
Loop Unrolling คือศิลปะการรีดความเร็วแบบดั้งเดิมที่พิสูจน์ให้เห็นว่า “โค้ดที่สั้นกว่า ไม่ได้แปลว่าจะทำงานเร็วกว่าเสมอไป” ครับ มันเป็นตัวอย่างที่ชัดเจนที่สุดของ Time-Space Trade-off ที่วิศวกกร Embedded ต้องเลือกใช้ให้ถูกจังหวะ เพื่อดึงประสิทธิภาพของ CPU และ Pipeline ออกมาให้ได้มากที่สุดครับ
หากเพื่อนๆ สนใจอยากลองเขียนโค้ดแล้วใช้ Tool อย่าง Compiler Explorer หรือเปิดไฟล์ .lst (Assembly List) ของ GCC เพื่อส่องดูว่า Compiler แอบคลี่ลูปให้เราหรือไม่ แวะเข้ามาตั้งกระทู้แชร์ภาพ Assembly โค้ดและพูดคุยกันต่อได้ที่บอร์ด www.123microcontroller.com ของพวกเราได้เลยนะครับ! แล้วพบกันใหม่ในบทความหน้า Happy Coding ครับทุกคน!