Algorithm Choice & Big O Notation: หัวใจหลักของ Optimization ที่ทรงพลังกว่าการแฮ็กโค้ดระดับล่าง!

บทนำ (Introduction)
สวัสดีครับน้องๆ วิศวกรและเพื่อนนักพัฒนาชาว www.123microcontroller.com ทุกคน! กลับมาพบกับวิศวกรขอบตาดำๆ กันอีกครั้งครับ เวลาที่เราพูดถึงคำว่า “Optimization (การรีดประสิทธิภาพโปรแกรม)” ในโลกของ Embedded Systems หรือ System Programming หลายคนมักจะนึกถึงการเขียนโค้ดแบบใช้ Bitwise Operations แปลกๆ, การเขียน Assembly แทรก, หรือการพยายามใช้ Register ของไมโครคอนโทรลเลอร์ให้คุ้มค่าที่สุด
แต่รู้หรือไม่ครับว่า แหล่งข้อมูลระดับปรมาจารย์ต่างเห็นพ้องต้องกันว่า การ Optimization ที่สำคัญและส่งผลลัพธ์ได้รุนแรงที่สุด มักจะเริ่มต้นจากการ “เลือกใช้อัลกอริทึมที่ถูกต้อง (Algorithm Choice)” ครับ การไปนั่งงมปรับแก้โค้ดระดับล่าง (Micro-optimization) แทบจะไม่มีประโยชน์เลย หากเรายังใช้โครงสร้างหรือวิธีการแก้ปัญหาที่ผิดตั้งแต่แรก
วันนี้เราจะมาคุยกันว่า ทำไมเราถึงต้องพึ่งพาสิ่งที่เรียกว่า Big O Notation มาเป็นไม้บรรทัดวัดความเหนื่อยของ CPU และมันมีความสำคัญในบริบทที่กว้างขึ้นของ Optimization อย่างไร ไปลุยกันเลยครับ!
เนื้อหาหลัก (Core Concept): ทำไม Algorithm Choice ถึงเป็นรากฐานของ Optimization?
ในบริบทของการพัฒนาซอฟต์แวร์ การทำ Optimization คือความพยายามที่จะลดการใช้ทรัพยากร (เช่น เวลาที่ใช้ประมวลผล หรือ หน่วยความจำ) ซึ่งการทำความเข้าใจและเลือกใช้อัลกอริทึมที่เหมาะสม เป็นการแก้ปัญหาที่ระดับ “สถาปัตยกรรม (Macro-optimization)” ซึ่งให้ผลลัพธ์ดีกว่าการไปแก้ที่ระดับโค้ดย่อยๆ เสมอ โดยมีหลักการคิดดังนี้ครับ:
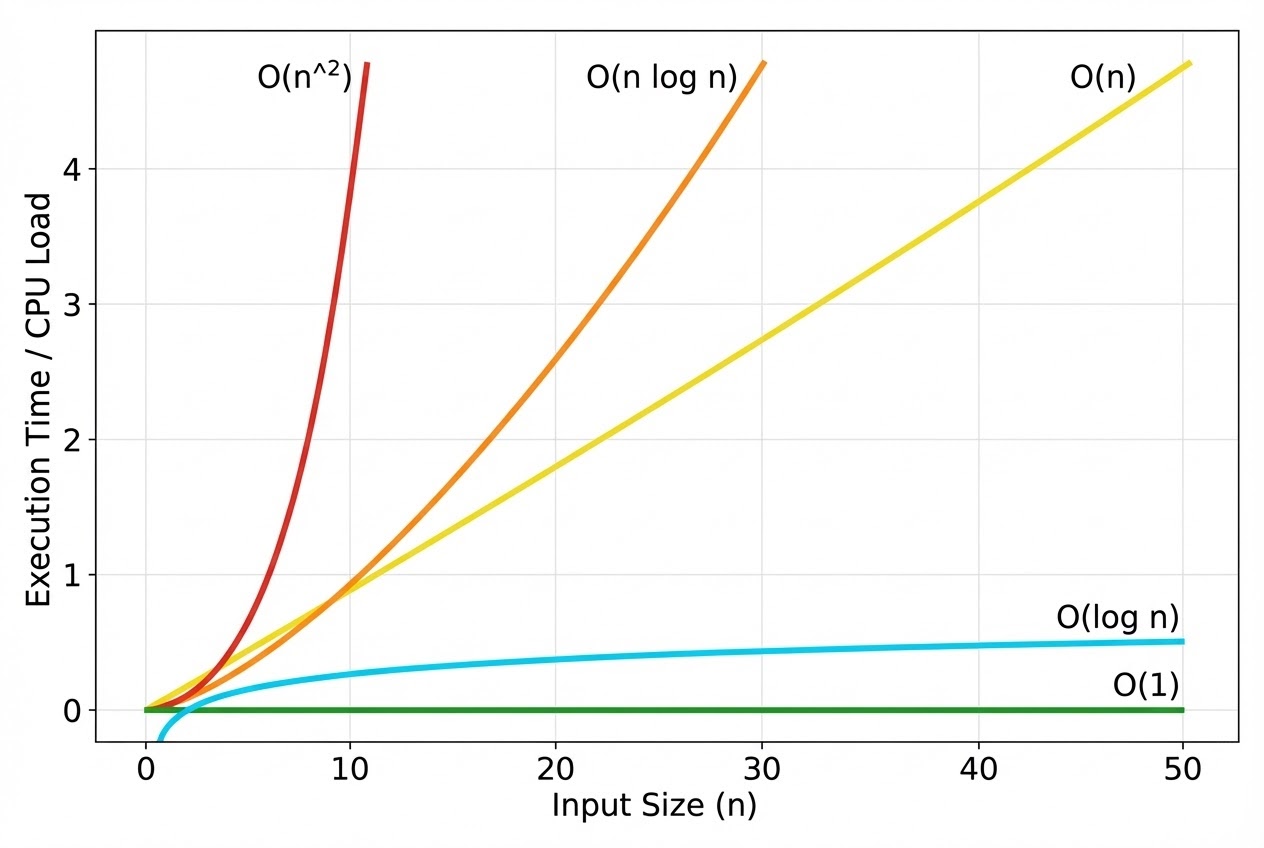
- 1. Big O Notation คืออะไร?: Big O หรือ $O(n)$ เป็นสัญลักษณ์ทางคณิตศาสตร์ที่ใช้เพื่ออธิบาย “ขอบเขตบน (Upper bound)” หรือ “กรณีที่แย่ที่สุด (Worst-case scenario)” ของการทำงานของอัลกอริทึมเมื่อขนาดของข้อมูล (Input size หรือ $n$) มีขนาดใหญ่ขึ้นเรื่อยๆ มันช่วยให้เรารู้ว่า ถ้ายัดข้อมูลเข้าไปให้ไมโครคอนโทรลเลอร์ประมวลผลเยอะๆ CPU ของเราจะทำงานหนักเพิ่มขึ้นในอัตราส่วนเท่าไหร่
- 2. การละทิ้งค่าคงที่ (Ignoring Constants): กฎเหล็กของ Big O คือเราจะไม่สนใจ “ค่าคงที่ (Constant factors)” ครับ ยกตัวอย่างเช่น หากอัลกอริทึมหนึ่งใช้เวลา $3n^2 + 10n + 10$ เมื่อ $n$ หรือจำนวนข้อมูลมีขนาดใหญ่มากๆ (เช่น ข้อมูลเซ็นเซอร์ล้านตัว) เทอมที่มีอิทธิพลต่อความช้าที่สุดคือ $n^2$ เท่านั้น เราจึงตีความแบบ Big O ได้ว่าอัลกอริทึมนี้มีความซับซ้อนระดับ $O(n^2)$ การลดค่าคงที่ (เช่น เปลี่ยนจาก $3n^2$ เป็น $1n^2$) คือสิ่งที่เราได้จากการทำ Micro-optimization ระดับล่าง แต่การเปลี่ยนจาก $O(n^2)$ ให้กลายเป็น $O(n)$ ต่างหาก คือเวทมนตร์ของการเปลี่ยน Algorithm!
- 3. ระดับความเร็ว (Complexity Classes) ที่เจอบ่อย:
- $O(1)$ Constant Time: ดีที่สุด! ไม่ว่าข้อมูลจะเยอะแค่ไหน เวลาทำงานก็เท่าเดิมเสมอ (เช่น การดึงค่าจาก Array ด้วย Index หรือการใช้ Lookup Table)
- $O(\log n)$ Logarithmic Time: เร็วมาก เพราะตัดข้อมูลทิ้งทีละครึ่งในทุกๆ รอบ (เช่น Binary Search)
- $O(n)$ Linear Time: เวลาเพิ่มขึ้นแปรผันตรงตามจำนวนข้อมูล (เช่น การวนลูปหาข้อมูลใน Array ตั้งแต่ต้นจนจบ หรือ Linear Search)
- $O(n \log n)$: มักพบในอัลกอริทึมการเรียงลำดับที่มีประสิทธิภาพ (เช่น Merge Sort, Quick Sort)
- $O(n^2)$ Quadratic Time: ยิ่งข้อมูลเยอะ เวลายิ่งพุ่งกระฉูด มักเกิดจากการใช้ลูปซ้อนลูป (Nested loops) (เช่น Bubble Sort หรือ Selection Sort)
- 4. Time-Space Trade-off (การแลกเปลี่ยนระหว่างเวลากับพื้นที่): ในงาน Embedded ระบบของเรามีทั้งข้อจำกัดด้านความเร็ว (Time) และหน่วยความจำ (Space) หลายๆ ครั้งเราสามารถทำ Optimization ให้โค้ดทำงานเร็วขึ้นได้โดยการยอม “เปลือง RAM” มากขึ้น เช่น การสละพื้นที่จอง Array ใหญ่ๆ เพื่อเก็บผลลัพธ์ล่วงหน้า (Lookup Tables) เพื่อให้อ่านค่าได้ในระดับ $O(1)$ แทนที่จะให้ CPU คำนวณสมการคณิตศาสตร์สดๆ ทุกครั้ง
ตัวอย่างโค้ด (Code Example): Linear Search vs Binary Search
ลองมาดูตัวอย่างการเลือกใช้อัลกอริทึมเพื่อค้นหาข้อมูลครับ สมมติว่าเรามี Array เก็บข้อมูลเรียงลำดับอยู่ 1,000 ตัว หากเราใช้การหาแบบไล่ทีละตัว (Linear Search) ในกรณีเลวร้ายที่สุด CPU ต้องวนลูปถึง 1,000 ครั้ง ($O(n)$)! แต่ถ้าเราเปลี่ยนมาใช้อัลกอริทึม Binary Search มันจะใช้เวลาค้นหาสูงสุดเพียงประมาณ 10 ครั้งเท่านั้น ($O(\log n)$) นี่แหละครับพลังของการเลือก Algorithm
#include <stdio.h>
#include <stdint.h>
#include <stdbool.h>
/*
* 1. อัลกอริทึม Linear Search: ความซับซ้อน O(n)
* ข้อดี: ง่าย ไม่ต้องเรียงข้อมูลก่อน
* ข้อเสีย: ช้ามากถ้า array มีขนาดใหญ่ (ข้อมูล 1,000,000 ตัว ก็อาจต้องหา 1,000,000 ครั้ง)
*/
int32_t linear_search(const int32_t arr[], uint32_t size, int32_t target) {
for (uint32_t i = 0; i < size; ++i) {
if (arr[i] == target) {
return i; /* เจอแล้ว คืนค่า Index */
}
}
return -1; /* ไม่เจอ */
}
/*
* 2. อัลกอริทึม Binary Search: ความซับซ้อน O(log n)
* ข้อกำหนด: Array ต้องถูก "เรียงลำดับ (Sorted)" มาก่อนเสมอ
* จุดเด่น: เร็วสุดๆ! หาข้อมูล 1,000,000 ตัว ใช้การวนลูปไม่เกิน 20 ครั้ง!
*/
int32_t binary_search(const int32_t arr[], uint32_t size, int32_t target) {
int32_t left = 0;
int32_t right = size - 1;
while (left <= right) {
/* หาจุดกึ่งกลาง (หาร 2) เพื่อหั่นขอบเขตการค้นหาทีละครึ่ง */
int32_t mid = left + (right - left) / 2;
if (arr[mid] == target) {
return mid; /* เจอแล้ว */
}
if (arr[mid] < target) {
left = mid + 1; /* ค่าเป้าหมายอยู่ครึ่งขวา */
} else {
right = mid - 1; /* ค่าเป้าหมายอยู่ครึ่งซ้าย */
}
}
return -1; /* ไม่เจอ */
}
int main(void) {
int32_t sorted_sensor_data[] = {10, 25, 32, 45, 50, 68, 72, 85, 90, 100};
uint32_t data_size = sizeof(sorted_sensor_data) / sizeof(sorted_sensor_data);
int32_t target_val = 68;
/* การเลือกใช้ Algorithm ที่ดี เป็นการ Optimize ที่เห็นผลชัดเจนที่สุด */
int32_t index = binary_search(sorted_sensor_data, data_size, target_val);
if (index != -1) {
printf("Found target %d at index %d\n", target_val, index);
} else {
printf("Target not found.\n");
}
return 0;
}
ข้อควรระวัง / Best Practices:
การเลือก Algorithm ด้วย Big O เป็นสิ่งที่ดี แต่ก็มีหลุมพรางที่โปรแกรมเมอร์มักพลาดครับ คัมภีร์วิศวกรรมซอฟต์แวร์แนะนำไว้ดังนี้:
- ระวังปีศาจแห่งการรีบ Optimize (Premature Optimization is the root of all evil): นี่คือวาทะกรรมคลาสสิกของศาสตราจารย์ Donald Knuth ครับ การพยายามเขียนโค้ดให้ซับซ้อนเพียงเพื่อลดเวลาเล็กๆ น้อยๆ ตั้งแต่เนิ่นๆ มักสร้างบั๊กมหาศาล จงโฟกัสที่การเขียนโค้ดให้อ่านง่ายและทำงานถูกก่อน จากนั้น “จงใช้เครื่องมือวัดผล (Profiler/Data)” เพื่อหาว่าโค้ดส่วนไหนช้าจริงๆ (Bottleneck) แล้วค่อยไป Optimize ตรงนั้นครับ อย่าเดาเอาเองเด็ดขาด!
- ระวังกับดักของ Input ขนาดเล็ก (Small n Issue): ใช่ครับ อัลกอริทึม $O(n \log n)$ นั้นเหนือกว่า $O(n^2)$ เสมอเมื่อข้อมูลมีจำนวนเป็นหมื่นเป็นแสน แต่ถ้าโปรเจกต์ของคุณรู้แน่ๆ ว่าจะมีข้อมูลให้ค้นหาแค่ 5-10 ค่า การใช้อัลกอริทึมพื้นฐานอย่าง $O(n^2)$ หรือ Linear Search $O(n)$ อาจจะทำงานได้เร็วกว่า! เพราะโครงสร้างมันง่าย (มีค่า Constant factor ต่ำ) กว่าอัลกอริทึมที่ซับซ้อนนั่นเองครับ
- อย่าสร้างล้อใหม่ถ้าไม่จำเป็น (Don’t reinvent the wheel): หากคุณต้องการใช้อัลกอริทึมที่ต้อง Optimize มาอย่างดีแล้ว เช่น การทำ FFT (Fast Fourier Transform) หรือการเรียงลำดับ ให้เรียกใช้ Library มาตรฐานของระบบหรือของผู้ผลิตชิป (เช่น DSP Library) เสมอ เพราะพวกเขาได้เขียนโค้ดผสานการทำงานกับ Hardware ไว้ได้อย่างรีดประสิทธิภาพสุดๆ แล้วครับ
สรุป (Conclusion)
ในภาพรวมของการทำ Optimization นั้น “Algorithm Choice” และการวิเคราะห์ด้วย Big O Notation คือเข็มทิศนำทางชิ้นแรกที่สำคัญที่สุดครับ! แทนที่เราจะเสียเวลาหลายวันไปกับการเขียน Assembly แบบหยุมหยิม สู้เราถอยออกมาหนึ่งก้าว แล้วเปลี่ยนโครงสร้างข้อมูลจาก Linked List มาเป็น Hash Table หรือเปลี่ยนลูป $O(n^2)$ เป็น $O(n \log n)$ แบบนี้จะเพิ่มความเร็วให้กับระบบฝังตัวของเราได้มหาศาลกว่ามากครับ
หากเพื่อนๆ สนใจอยากดูวิธีการประยุกต์ใช้ Data Structure แปลกๆ เข้ากับไมโครคอนโทรลเลอร์ที่มี RAM จำกัดจำเขี่ย หรือใครเคยเผลอทำลูปอนันต์จนระบบค้างมาแล้ว (พี่ล่ะคนนึง! 😅) แวะเข้ามาตั้งกระทู้แชร์ประสบการณ์และพูดคุยกันต่อได้ที่บอร์ด www.123microcontroller.com ของพวกเราได้เลยนะครับ! แล้วพบกันใหม่ในบทความหน้า Happy Coding ครับทุกคน!