เจาะลึกสมองกล STM32: ทำความรู้จักสถาปัตยกรรม Processor Core และการทำงานภายใน

เจาะลึกสมองกล STM32: ทำความรู้จักสถาปัตยกรรม Processor Core และการทำงานภายใน
สวัสดีครับเหล่า Maker และ Embedded Developer ทุกท่าน! ยินดีต้อนรับเข้าสู่คลาสเจาะลึกฮาร์ดแวร์กับ 123Microcontroller.com ครับ
วันนี้เราจะมา “ผ่าตัดสมอง” ของบอร์ด STM32 กันครับ หลายคนเขียนโค้ด main() วนลูปไปมา แต่ไม่เคยรู้เลยว่าข้างใน “ก้อนซิลิกอน” สีดำๆ นั้น มันมีกลไกการคิดและสั่งการอย่างไร
จากกองเอกสาร Datasheet และ Reference Manual ที่เรามี ผมได้สรุปเรื่อง “แกนประมวลผล (Processor Core)” ในมุมมองของฮาร์ดแวร์ออกมาเป็นบทความที่ย่อยง่ายที่สุด ดังนี้ครับ
ระดับความยาก: ⭐⭐⭐ (ทฤษฎีฮาร์ดแวร์เชิงลึก) เวลาที่ใช้: 15 นาที
1. แกนประมวลผลคืออะไร? (The Heart of the Beast)
ในโลกของ STM32 คำว่า “Core” หรือแกนประมวลผล ไม่ได้หมายถึงทั้งตัวชิปนะครับ แต่มันหมายถึง ARM Cortex-M Processor ซึ่งเป็น “พิมพ์เขียว” ที่บริษัท ST ซื้อลิขสิทธิ์มาจากบริษัท ARM Holdings เพื่อมาใส่ในชิปของตัวเองอีกที
STM32 เลือกใช้ตระกูล Cortex-M (Microcontroller Profile) ซึ่งออกแบบมาเพื่องาน Embedded โดยเฉพาะ โดยแบ่งรุ่นตามความสามารถดังนี้:
- Cortex-M0/M0+: น้องเล็ก เน้นประหยัดไฟและราคาถูก (เจอใน STM32F0, L0)
- Cortex-M3: รุ่นพี่คนกลาง สมดุลดีเยี่ยม (เจอใน STM32F1)
- Cortex-M4: รุ่นอัปเกรด เพิ่มความสามารถคำนวณเลขทศนิยม (FPU) และ DSP (เจอใน STM32F4, G4)
- Cortex-M7: พี่ใหญ่ บ้าพลัง ประมวลผลเร็วที่สุด (เจอใน STM32F7, H7)
2. สถาปัตยกรรม: ถนนหลายสายไม่อายทำกิน
นี่คือความลับที่ทำให้ STM32 (M3/M4/M7) ทำงานเร็วกว่าชิป 8-bit รุ่นเก่าๆ มหาศาลครับ นั่นคือการบริหารจัดการ “ถนน” หรือ Bus ในการขนส่งข้อมูล
Von Neumann vs. Harvard Architecture
- Von Neumann (แบบเก่า/M0): ใช้ถนนเส้นเดียว (Bus) ทั้งขนส่ง “คำสั่ง” (Code) และ “ข้อมูล” (Data) ทำให้ต้องรอคิวกัน รถติด!
- Harvard Architecture (แบบใหม่ M3/M4): แยกถนนขาดจากกัน!
- I-Code Bus: สำหรับดึงคำสั่งจาก Flash โดยเฉพาะ
- D-Code Bus: สำหรับดึงข้อมูลตัวแปรจาก Memory
- System Bus: สำหรับคุยกับ Peripherals ต่างๆ
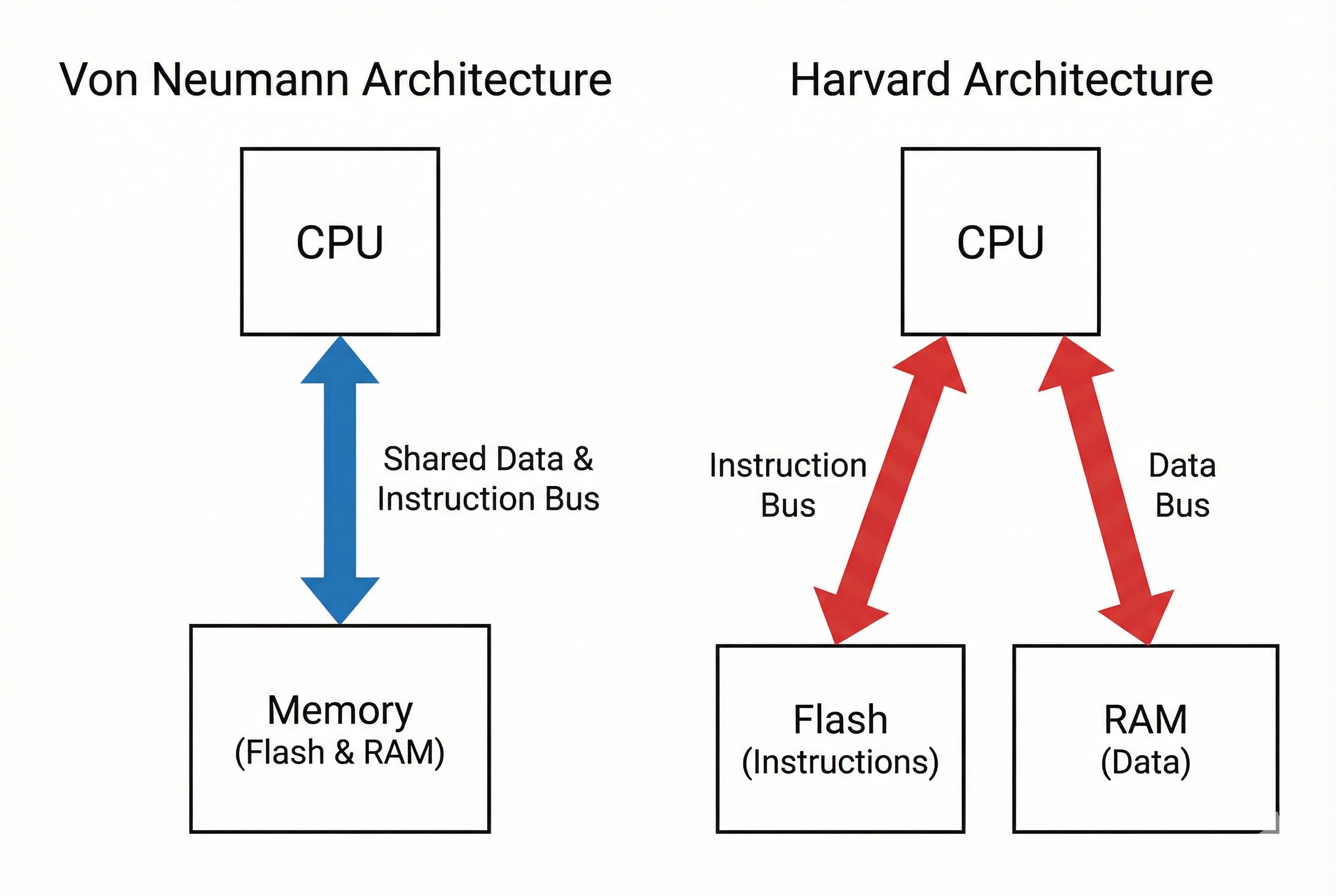
ผลลัพธ์: CPU สามารถ “อ่านคำสั่งถัดไป” พร้อมๆ กับ “บันทึกค่าตัวแปร” ได้ในเวลาเดียวกัน (Simultaneous Access) ทำให้ทำงานได้เต็มประสิทธิภาพทุก Clock Cycle
หมายเหตุ: ในเอกสารระบุว่า Cortex-M0 (STM32F0) ยังใช้แบบ Von Neumann อยู่เพื่อลดขนาดวงจร แต่รุ่น M3/M4 ขึ้นไปเป็น Harvard หมดแล้วครับ
3. ท่อส่งคำสั่ง (Pipeline): โรงงานผลิต 3 ขั้นตอน
ภายใน Core ไม่ได้ทำงานโป้งเดียวจบ แต่ทำงานเป็นสายพานการผลิต (Pipeline) แบบ 3 ขั้นตอน (สำหรับ M3/M4):
- Fetch: ไปหยิบคำสั่งมาจาก Flash
- Decode: แปลความหมายว่าคำสั่งนี้ให้ทำอะไร (บวก, ลบ, กระโดด)
- Execute: ลงมือทำจริง (สั่ง ALU คำนวณ)
ข้อดี: ในขณะที่คำสั่งที่ 1 กำลัง Execute, คำสั่งที่ 2 ก็กำลังถูก Decode และคำสั่งที่ 3 ก็กำลังถูก Fetch เข้ามา ทำให้ทุกๆ จังหวะนาฬิกา มีงานเสร็จออกมาตลอดเวลา
เกร็ดเสริม: สำหรับ Cortex-M7 นั้นเทพกว่ามาก เพราะใช้ Pipeline ถึง 6 ขั้นตอน และเป็นแบบ Superscalar (ทำ 2 คำสั่งพร้อมกันได้)
4. ชุดคำสั่ง (Instruction Set): Thumb-2 Technology
นี่คือพระเอกของ ARM ครับ! สมัยก่อนชิป 32-bit จะกินที่เก็บโปรแกรมเยอะมาก แต่ Cortex-M ใช้เทคโนโลยี Thumb-2
ความเจ๋ง: มันผสมผสานคำสั่งขนาด 16-bit (สั้นกะทัดรัด) และ 32-bit (ทรงพลัง) เข้าด้วยกันในโปรแกรมเดียวโดยอัตโนมัติ ผลลัพธ์: ได้ความเร็วแบบ 32-bit แต่ขนาดไฟล์เล็กเกือบเท่า 16-bit (High Code Density)
5. อาวุธลับ: FPU (Floating Point Unit)
สำหรับชาว STM32F4 (Cortex-M4F) เรามีของดีที่รุ่น F1 ไม่มี นั่นคือ Hardware FPU
- คืออะไร: วงจรพิเศษสำหรับคิดเลขทศนิยม (
float) - ทำไมต้องมี: ถ้าไม่มี FPU (เช่นใน M3) CPU ต้องใช้คำสั่งพื้นฐานหลายร้อยบรรทัดเพื่อจำลองการบวกเลขทศนิยม แต่ถ้ามี FPU มันสั่ง
VADD.F32คำสั่งเดียว จบใน 1 Cycle! - การใช้งาน: ต้องเปิดใช้ในโค้ดก่อน (ปกติ
SystemInit()ทำให้) และใน Compiler ต้องเลือก-mfloat-abi=hard
6. การเชื่อมต่อ: Bus Matrix จราจรอัจฉริยะ
เปรียบเทียบระบบภายในเหมือนเมืองที่มีถนน (Bus) เชื่อมต่อกัน โดยมี Bus Matrix เป็นวงเวียนจราจรขนาดใหญ่
- Masters (ผู้สั่งการ): Core และ DMA (Direct Memory Access)
- Slaves (ผู้รับคำสั่ง): Flash, SRAM, และ Peripherals
หน้าที่: Bus Matrix จะคอยสับราง ถ้า Core คุยกับ Flash และ DMA คุยกับ SRAM มันจะให้ทำพร้อมกันได้เลย แต่ถ้าแย่งกันคุยกับ SRAM ตัว Matrix จะจัดคิวให้ (Arbitration)
สรุป: สิ่งที่ Developer ต้องรู้ (Verdict) 💡
- เลือก Data Type ให้ถูก: แม้จะเป็น 32-bit Core แต่การบวกเลข 8-bit, 16-bit, 32-bit ใช้เวลาเท่ากัน (1 cycle) เพราะ Register ภายในกว้าง 32-bit ดังนั้นถ้าไม่ติดเรื่องขนาด RAM ใช้
int32_tหรือintไปเลยมักจะเร็วที่สุดครับ - FPU ไม่ได้ทำงานเอง: อย่าลืมเปิด FPU ในการตั้งค่า Compiler ไม่งั้นโค้ดคำนวณทศนิยมจะอืดมากเพราะไปใช้ Software Library แทน
- ระวังคอขวด: แม้ Core จะเร็วมาก แต่ถ้า Flash ส่งข้อมูลให้ไม่ทัน (Flash Latency) ความเร็วก็ตกได้ ดังนั้นอย่าลืมเปิด ART Accelerator (Cache) ของ STM32F4 เสมอครับ
หวังว่าบทความนี้จะทำให้คุณมองเห็นภาพ “หัวใจ” ที่เต้นอยู่บนบอร์ด STM32 ของคุณชัดเจนขึ้นนะครับ! 🚀