Inside the Silicon Brain: STM32 Processor Core Architecture Explained

Inside the Silicon Brain: STM32 Processor Core Architecture Explained
Hello Makers and Embedded Developers! Welcome to another deep dive at 123Microcontroller.com.
Today, we are going to perform brain surgery on our STM32 boards. Many of us write main() loops daily without ever truly understanding what happens inside that black square of silicon.
Based on datasheets and the ARM Reference Manuals, we are going to explore the “Processor Core” within the hardware architecture context. Here is the breakdown of how the machine thinks.
Difficulty: ⭐⭐⭐ (Deep Hardware Theory) Time: 15 Minutes
1. What is “The Core”? (The Heart of the Beast)
In the STM32 ecosystem, the “Core” doesn’t refer to the entire chip, but specifically to the ARM Cortex-M Processor. This is the intellectual property (IP) or “blueprint” that STMicroelectronics licenses from ARM Holdings to integrate into their silicon.
STM32 utilizes the Cortex-M (Microcontroller Profile) family, designed specifically for embedded applications. Here is the lineup:
- Cortex-M0/M0+: The entry-level efficiency experts (Found in STM32F0, L0).
- Cortex-M3: The balanced middle sibling (Found in STM32F1).
- Cortex-M4: The performance upgrade, featuring DSP and FPU capabilities (Found in STM32F4, G4).
- Cortex-M7: The powerhouse, offering the highest processing speeds (Found in STM32F7, H7).
2. Architecture: The Highway System
This is the secret sauce that makes STM32 (M3/M4/M7) significantly faster than older 8-bit architectures. It essentially comes down to how the chip manages traffic.
Von Neumann vs. Harvard Architecture
- Von Neumann (Legacy/M0): Uses a single bus for both “Instructions” (Code) and “Data” (Variables). This creates a bottleneck—the CPU must wait for code before it can fetch data.
- Harvard Architecture (M3/M4/M7): Separate highways!
- I-Code Bus: Dedicated to fetching instructions from Flash.
- D-Code Bus: Dedicated to data access from Memory.
- System Bus: Handles communication with peripherals.
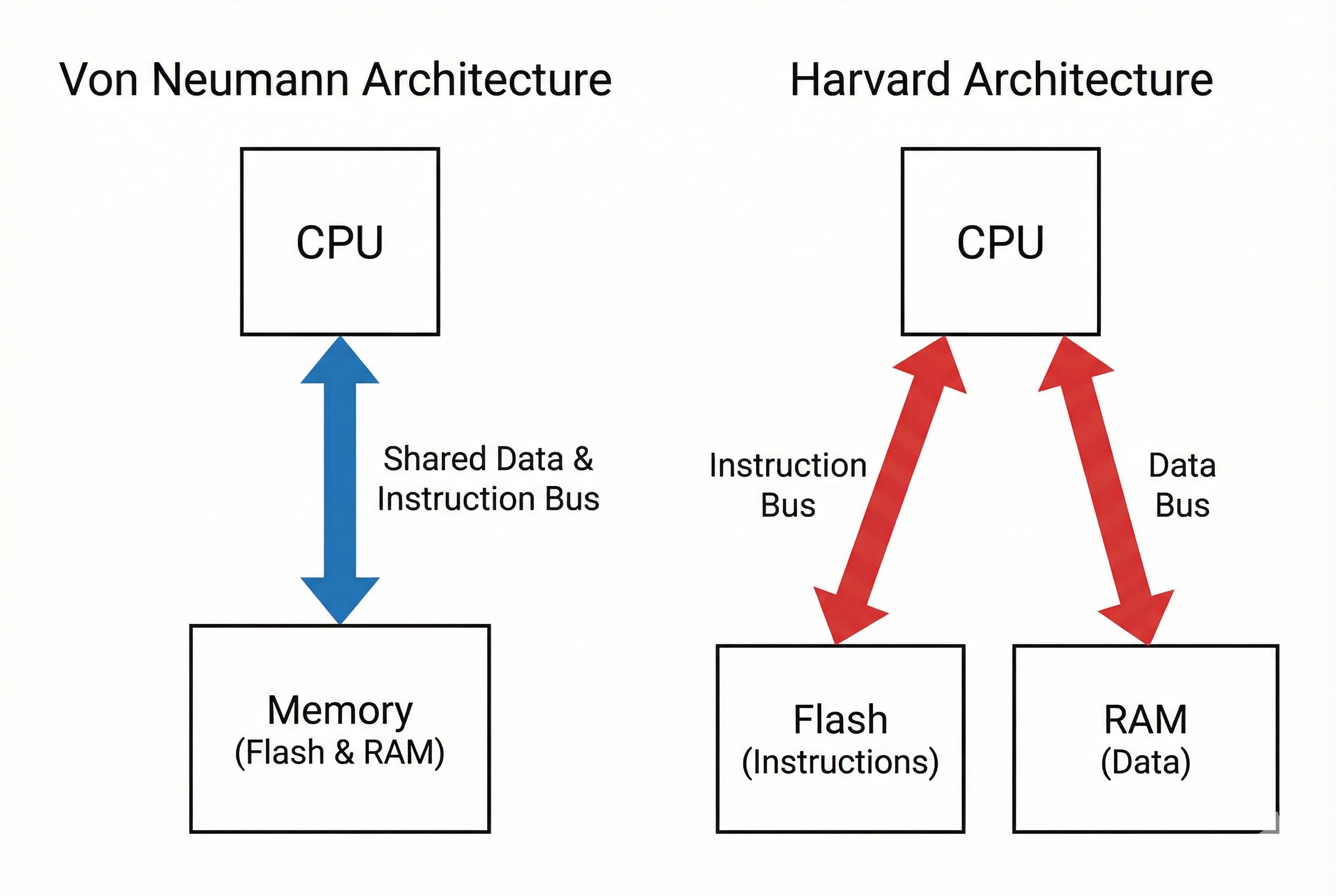
The Result: The CPU can “read the next instruction” and “write a variable value” simultaneously. This allows for maximum efficiency in every clock cycle.
Note: Cortex-M0 (STM32F0) still utilizes Von Neumann architecture to minimize circuit size and cost.
3. The Pipeline: The 3-Stage Factory
The Core doesn’t execute tasks in a single step. It operates like a factory assembly line, specifically a 3-Stage Pipeline (for M3/M4):
- Fetch: Grab the instruction from Flash.
- Decode: Translate the instruction (Add, Subtract, Jump).
- Execute: Perform the action (ALU calculation).
Why it matters: While Instruction #1 is being Executed, Instruction #2 is being Decoded, and Instruction #3 is being Fetched. This means work is completed on every clock tick.
Pro Tip: The Cortex-M7 is even more advanced with a 6-stage pipeline and Superscalar capabilities (executing two instructions at once).
4. Instruction Set: Thumb-2 Technology
This is ARM’s ace in the hole. Historically, 32-bit chips required large amounts of storage for their programs. Thumb-2 Technology solves this.
It automatically blends 16-bit instructions (compact) and 32-bit instructions (powerful) within the same program. The Verdict: You get 32-bit performance with a code size density almost as small as a 16-bit architecture.
5. Secret Weapon: FPU (Floating Point Unit)
For STM32F4 (Cortex-M4F) users, you have a distinct advantage over the F1 series: Hardware FPU.
- What is it? A specialized circuit for floating-point math (
float). - Without FPU: The CPU uses hundreds of software instructions to simulate decimal addition.
- With FPU: The CPU executes a single instruction (
VADD.F32) and finishes in 1 Cycle!
Developer Tip: You must enable the FPU in your compiler settings (usually
-mfloat-abi=hard) and ensureSystemInit()runs at startup.
6. The Bus Matrix: Intelligent Traffic Control
Imagine the internal system as a city with roads (Buses). The Bus Matrix is the giant roundabout connecting everything.
- Masters (Commanders): Core and DMA (Direct Memory Access).
- Slaves (Receivers): Flash, SRAM, and Peripherals.
The Bus Matrix manages arbitration. If the Core talks to Flash and the DMA talks to SRAM, they can operate simultaneously. If they both try to access SRAM, the Matrix queues them efficiently.
Verdict: What Developers Need to Know 💡
- Data Types Matter: Even though it is a 32-bit Core, adding 8-bit, 16-bit, or 32-bit numbers takes the same amount of time (1 cycle) because the internal registers are 32-bit wide. When in doubt, use
int32_torintfor speed (unless RAM is tight). - FPU isn’t Automatic: Always check your compiler flags. If FPU isn’t enabled, your math-heavy code will crawl using software libraries.
- Beware of Latency: The Core is fast, but sometimes Flash memory can’t keep up. Always enable the ART Accelerator (Cache) on STM32F4/F7 to prevent the CPU from stalling while waiting for instructions.
I hope this article gives you a clearer picture of the “heart” beating inside your STM32 projects! 🚀