Memory Pools (Fixed-size Blocks): The Ultimate Tactical Reservoir for Dominating Embedded Data Structures

Introduction: The Ultimate Architectural Defense Against Memory Fragmentation
Greetings hardware engineers, embedded specialists, and fellow developers at www.123microcontroller.com! Today, the dark-eyed engineer returns to dissect a lethal high-level architectural paradigm directly interlinking the chaotic realm of bare-metal Memory Management into the absolute rigid structures of advanced Data Structures: we are unleashing the science behind Memory Pools.
In high-level application C programming, when architects desire to deploy dynamically adapting Data Structures—powerful vectors spanning complex Linked Lists, aggressive Binary Trees, or massive Priority Queues—they lazily pull the malloc() and free() trigger to fabricate and incinerate independent “Nodes”. However, transitioning this philosophy into the hyper-lethal arena of strict hardware integration and Safety-Critical Embedded Systems mutates that process into a profound engineering nightmare! Standard dynamic allocation radically injects cancerous Memory Fragmentation and forces the CPU to burn completely erratic, Non-Deterministic processor cycles.
To permanently eradicate this chaotic variable, veteran C programming warlords innovated a brutal and highly constrained memory architecture categorized as Memory Pools (or strictly: Fixed-size block allocation). Today, we are strapping in to examine precisely how leading engineering doctrines enforce this exact technique to mathematically stabilize the most viciously unstable Data Structures known to modern engineering.
What is a Memory Pool, and Why Do Advanced Data Structures Demand It?
In an oversimplified architectural parallel, rapidly machine-gunning malloc() is mathematically equivalent to “halting processing to fully construct a brand-new house specifically every instance a new resident appears.” You annihilate operational overhead searching for geographical land and importing contractors (Massive OS Overhead). Conversely, a rigidly enforced Memory Pool equates to “Pre-calculating and Pre-allocating a monstrous High-Rise apartment building consisting flawlessly of uniform identical rooms prior to runtime.” When an incoming data resident inevitably arrives, you hurl them an available room key with zero delay (Astronomical Speed!) and upon eviction, you merely flag that specific suite as available for the subsequent entity.
Zooming out into the macroscopic perspective of overarching Data Structures, elite engineering texts explicitly decode the undeniable systemic necessity and underlying mechanics of Memory Pools as follows:
- 1. Artificially engineered solely for Linked Lists and Trees: These brutally complex topological architectures are characterized by demanding the ceaseless mass-production of hundreds of distinct Object “Nodes” possessing the absolute identical bytecode dimension strictly mathematically derived by
sizeof(struct node). Forcing the CPU to pre-deploy a Memory Pool strictly configured as Fixed-Size Blocks mathematically aligned for these specific Nodes provides the single most flawless methodology on Earth to entirely bypass the horrifying processing overhead dragged in by standard OS Heap Managers. - 2. Total and Absolute Annihilation of Memory Fragmentation: Because all partitioned Memory Blocks entombed within the structure of a Pool are algorithmically forged to be identically cloned in byte-size, the topological landscape is strictly classified under binary physics: “Violently Allocated (Active)” or “Absolutely Free (Void)”. When a process successfully surrenders memory space back, it mathematically guarantees a void perfectly mirroring the exact byte-footprint demanded by the next incoming clone Node. This binary architectural paradigm categorically executes and permanently buries the threat of generating useless microscopic shrapnel fragments of fragmented memory (External Fragmentation).
- 3. Shock-and-Awe Mass Deallocation Campaigns: This represents an unprecedented tactical advantage! Assume the system has successfully cultivated a horrifyingly massive, multidimensional Data Structure resembling a colossal unbalanced Binary Tree. Opting to demolish it employing traditional
free()mandates the engineer to meticulously author dangerous Recursive logic, forcing the CPU to crawl and systematically assassinate nodes branch by branch—decimating CPU time and pushing the Call Stack to the absolute precipice of an Overflow explosion. Deploying a structured Pool, however, affords the developer the godly power to “Incinerate and format the entire designated Pool cluster in a solitary command execution.” Every single node currently tethered to that monolithic Tree instantly vaporizes, returning the RAM blocks intact to the free-state array in nanoseconds. - 4. Silicon-locked Deterministic Execution Latency: Operating deeply embedded within hard-Real-Time Operating Systems (RTOS) managing mission-critical physical hardware, reserving and liberating Memory via a tightly packed Pool can be structurally optimized so the machine code always resolves mathematically within universally constant execution cycles (O(1) Absolute Time Complexity). This aggressively rejects the algorithmic unpredictability innate to a standard
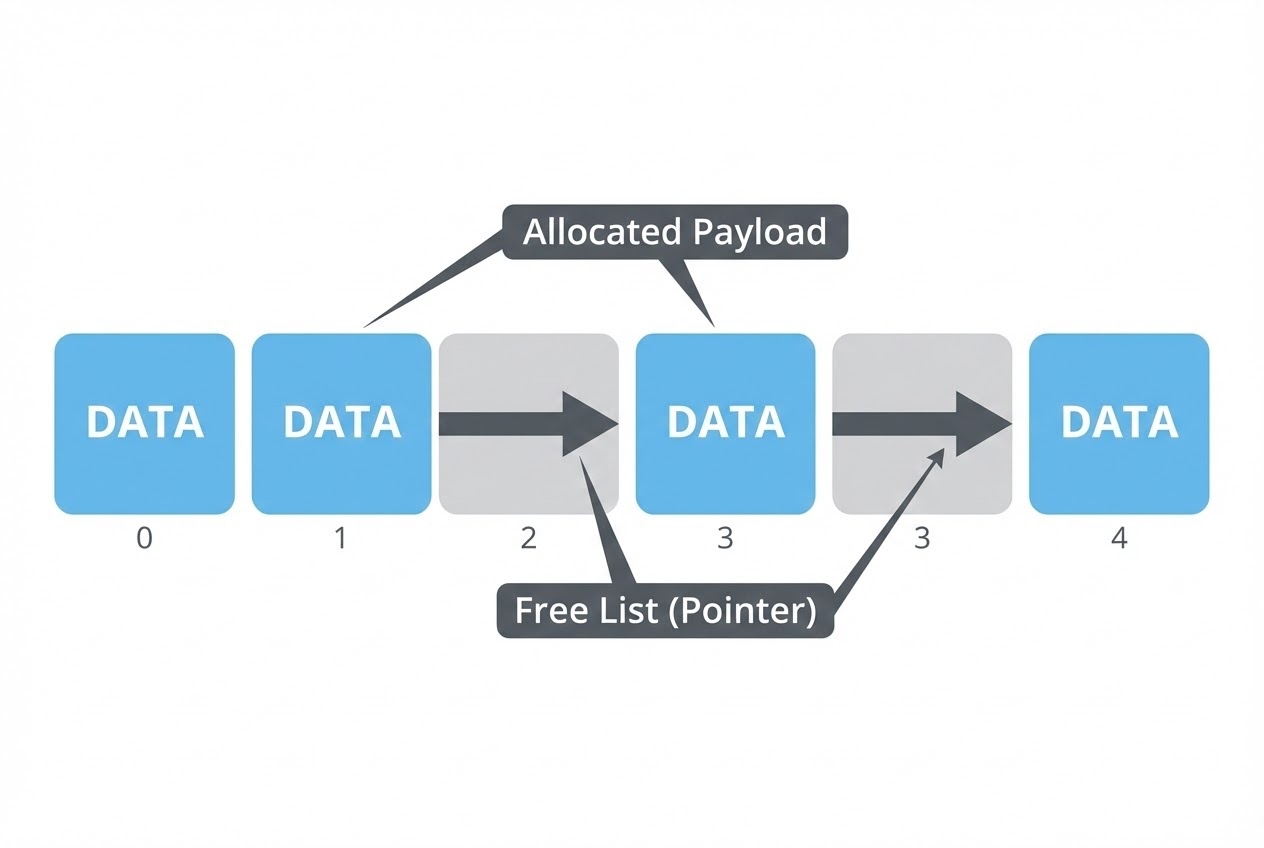
malloc(), where the overarching system frequently bleeds processor time aimlessly scanning scattered fragmented chunks across a destroyed Heap looking for sufficient contiguous bits. - 5. The Union-driven “Free List” Core Hack: To ruthlessly monitor and index precisely which slots within the Pool matrix remain unoccupied, elite architects weave an invisible, secondary Linked List directly overlaying the vacant blocks. This phantom architecture operates exclusively utilizing the sheer, unrelenting power of the C-language
unionkeyword. While a targeted slot is designated “Available State,” the physical RAM occupying that grid coordinate acts strictly as a raw Pointer, vectoring directly to the subsequent unoccupied block in the pipeline. Instantaneously upon application logic “claiming” that slot to instantiate a live Data Structure Node, that very same physical RAM byte is forcefully overwritten with active Payload Data. This elite wizardry achieves ultimate tactical supremacy by dictating that zero supplemental “Overhead Memory” bytes are sacrificed merely to operate the management Queue subsystem!
Code Exhibition: Fusing a Memory Pool With High-Velocity Union Tactics
Prepare to dissect an absolute masterpiece of low-level data architecture. This code physically hard-codes a Static Array-based Memory Pool utilizing a highly calculated Free List architecture. It explicitly commanders the union framework to dispatch rigid payload blocks acting as nodes within a Linked List/Tree topology. This represents the hyper-optimized code blueprint physically deployed within heavy-duty Embedded military and industrial sectors across the globe.
#include <stdio.h>
#include <stdbool.h>
#define POOL_SIZE 10 // Mission Parameters: Hardware restricted to an absolute maximum ceiling of 10 Data Structure Nodes
/* 1. Blueprint the Payload matrix our targeted Data Structure is demanding to host */
typedef struct {
int data;
void *next_node; // Relational Navigation Pointer explicitly designed to bridge Linked Lists or traverse Tree topologies
} PayloadData;
/*
* 2. The Heavy Artillery of Memory Domination: Forging a Union
* By collapsing raw Payload Data and the Free List Manager logic precisely into the same RAM vector,
* this hack entirely obliterates management memory overhead once the Node switches to "Active Lockdown" mode.
*/
typedef union PoolNode {
union PoolNode *next_free; // Phantom Dimension: When this Node is "Vacant/Void" (Acting exclusively as a Queue pointing to the next void)
PayloadData payload; // Tactical Dimension: When this Node is "Aggressively Locked into Data Storage"
} PoolNode_t;
/* 3. Requisition a heavily fortified Static Array sector during compile-time to accommodate stringent microcontroller limits */
static PoolNode_t node_pool[POOL_SIZE];
static PoolNode_t *head_free_list = NULL; // The Alpha Targeting Pointer actively scanning for initial voids
/* 4. Ignition Sequence Initializer: Aggressively wire every idle Node together, forging the initial Free List chain */
void pool_init(void) {
for (int i = 0; i < POOL_SIZE - 1; i++) {
node_pool[i].next_free = &node_pool[i + 1]; // Daisy-chain all hardware sectors directionally forward
}
node_pool[POOL_SIZE - 1].next_free = NULL; // Terminate structural vector; the absolute cliff edge
head_free_list = &node_pool[0]; // Lock targeting reticle onto grid 0
}
/* 5. Node Dispatch Protocol (Hyper-optimized O(1) latency matrix) - Deployed specifically as a lethal replacement for standard malloc() */
PayloadData* pool_alloc_node(void) {
if (head_free_list == NULL) {
printf("CRITICAL HARDWARE ALARM: Pool Matrix Exhausted - System Starving! (Out of Memory Flag)\n");
return NULL; /* Execute immediate tactical retreat; reject memory grant */
}
// Physically extract the Alpha Target Node resting patiently at the vanguard
PoolNode_t *allocated_node = head_free_list;
// Mathematically shift the Alpha Head Queue pointer to aggressively lock onto the subsequent available backup block
head_free_list = allocated_node->next_free;
return &(allocated_node->payload); // Transmit the highly secured structural coordinate back to the calling Application Logic
}
/* 6. Node Re-assimilation Protocol (Savage O(1) processing speed) - Deployed specifically to replace the treacherous free() */
void pool_free_node(PayloadData *node_to_free) {
if (node_to_free == NULL) return; // Immediate safeguard abort sequence defending against lethal Phantom Null Pointer bombings
// Execute a low-level Cast operation, violently stripping the Payload Data structure back down into the foundational Pool Node entity matrix
PoolNode_t *freed_node = (PoolNode_t *)node_to_free;
// Aggressively ram this freshly cleared memory block immediately onto the front lines, forging it as the new vanguard of the Free List hierarchy
freed_node->next_free = head_free_list;
head_free_list = freed_node; // The rejected Node officially reigns supreme as priority priority target number one
}
int main(void) {
pool_init(); // Boot the core management engine
PayloadData *my_node1 = pool_alloc_node();
if (my_node1) {
my_node1->data = 99;
printf("Successfully Allocated payload register: %d\n", my_node1->data);
}
pool_free_node(my_node1); // Terminate object lease and blast the memory block back into the centralized void
return 0;
}
Neutralizing Lethal Threats Invading Pool Operations
While operating a meticulously balanced Memory Pool serves as an omnipotent architectural cheat code scaling Embedded Data Structures safely, it inherently introduces an array of brutal technical minefields that senior hackers strongly mandate monitoring indefinitely:
- The Apocalyptic Null Space of Dangling Pointers (Zombies): This signifies the absolute zenith of execution risk probability! If the core logic officially surrenders an obsolete node back into the centralized matrix via
pool_free_node, yet a mathematically rogue Pointer concealed deep within a secondary module stealthily retains aim at that exact coordinate block—and catastrophically executes a “Write Operation”—that incoming garbage data brutally overwrites and mutilates the crucial internal pointer chaining algorithms (next_free) governing the overarching Free List. Simultaneously upon attempting to recycle that newly corrupted node for the next operation, the CPU hurls the primary firmware execution state aggressively into a catastrophic Crash (Classified heavily as a lethal Segmentation Fault Hardware Halt), shutting down the microcontroller violently mid-task! - The Abyss of Universal Generic Pool Alignment Errors: Attempting to achieve God-Status by manually authoring an omni-capable Generic Memory Pool architecture to effortlessly mimic
mallocusingvoid *capabilities is a notoriously volatile scenario. Senior developers are absolutely required to physically dissect the fundamental CPU schematic, aligning every assigned Block Size parameter perfectly onto the targeted hardware grid constraints (mathematically locking sectors strictly aligned onto 4-byte or natively 8-byte hardware block ratios based on silicon models). Permitting unaligned Byte reads instantly enrages the processing unit to execute unforgiving Hardware Exceptions the millisecond a logic misalignment executes a memory extraction. - The Dead End Limitations of the Fixed Capacity Cage: The tactical weakness embedded deeply within assigning the Memory Pool onto a rigid Static Array footprint involves its inescapable Threshold parameter. Once the algorithm completely bleeds dry its physical buffer reserves and impacts the memory limit ceiling (Exhaustion Event horizon), the active Data Structure array instantly halts all growth potential. Architecting a truly robust bare-metal application unconditionally mandates rigorously simulating catastrophic Worst-Case Payload Stress limits to mathematically calibrate and reserve sufficient maximum pool depths before compile-time. (Certain 100x engineers have hacked counter-measure logic to randomly construct modular Sub-Pool colonies scaling dynamically outside the primary ring, but this dangerously spikes internal calculus complexity, directly inviting structural failure logic traps.)
Conclusion
When evaluated within the immense macro-architecture underlying the global pantheon of advanced Data Structures, deploying hardcore Memory Pools radically transcends simple “alternative convenience”—it represents the unbreakable “Industry Mandate” rigidly clamped over true Embedded Systems and Real-Time Software Engineering execution parameters. It functions flawlessly as the ultimate bridge logic: seizing the undeniable supremacy of pristine Static Memory (Lightning execution speed, 100% Deterministic reliability, Zero structural Heap Fragmentation interference) and flawlessly weaponizing it with the chaotic power of unrestricted Dynamic Memory architecture (Mutating into highly fluid algorithms dictating flexible Linked Lists terminating rigid Array limits or expanding endless Binary Tree networks). By successfully synergizing these conflicting models, elite physical hackers ruthlessly squeeze max-level, benchmark-crushing efficiency cycles physically out of their microcontrollers, maxing processor capabilities hard into the digital redline.
It is highly anticipated this brutal mechanical dissection aggressively shatters misconceptions and mathematically clarifies the deep symbiotic resonance interlinking abstract Data Structure dimensions with physical metallic Silicon RAM memory layouts, sharpening your systemic perspective tremendously. Should any veteran “Shadow Coder” among you possess battle scars constructing custom Free List architectures by sheer force of logic, or having agonizingly immolated circuit boards under the sheer weight of zombie Memory Leaks consuming their entire silicon universe, punch your credentials into the forums! Display your battle-damaged codes and philosophize on structural algorithms in the ultimate engineering hack-station located within www.123microcontroller.com community! Stay primed; the next catastrophic battlefront dismantling maximum threat-level hardware engineering awaits in our upcoming architecture breakdown! Happy Coding, Cyber-Soldiers!