A Masterclass in C++ Foundations and Memory Management

Understanding C++ Memory Management for Embedded Systems
As a Software Architect or embedded systems engineer, simply understanding the “syntax” of C++ is not enough. To build high-performance, safe, and robust systems—whether you’re working on Edge Machine Learning with an ESP32, dealing with RTOS concurrency, or crunching geometric algorithms—you must understand the “mechanisms behind the scenes,” particularly memory management and data structures.
This guide summarizes core principles, linking them to real-world developmental scenarios.
1. C++ Program Structure
A solid C++ program begins with clear architectural structuring. This consists of including necessary headers, defining data structures, and establishing the entry point.
#includeDirectives: Used to pull in capabilities from robust libraries. For instance,<atomic>and<thread>for concurrent operations, or<nlohmann/json.hpp>for handling JSON data in Machine Learning pipelines.- The
main()Function: The universal entry point of your executable code. In RTOS environments, this might beapp_main()or a default thread. - Scope: Braces
{ }do much more than group code visually. They define the “lifecycle” of variables, dictating exactly when objects are created and destroyed. The semicolon;terminates statements.
Architectural Example:
#include <iostream>
#include <atomic>
#include <nlohmann/json.hpp> // Essential for ML data parsing
// Defining a struct for geometry processing
struct Point {
double x, y;
};
int main() {
// Instantiating an object on the Stack
Point p{10.5, 20.0};
{
// Inner Scope
std::atomic<int> counter(0);
counter.store(1, std::memory_order_relaxed);
} // 'counter' is automatically cleanly destroyed here (Stack Unwinding)
return 0;
}
2. Variables and Data Types
In resource-constrained environments like microcontrollers, or performance-critical ML algorithms, your choice of data type directly impacts memory footprint and computational precision.
| Data Type | Description |
|---|---|
int |
Standard integer. Useful for general counting or array indexing. |
uint32_t |
A 32-bit unsigned integer. Excellent for system IDs, hardware registers, or precise byte-counting. |
double |
High-precision floating-point number. Crucial for coordinates (x, y in Point or vectors). Note: On standard microcontrollers, float might be preferred if hardware lacking double-precision FPU is used. |
bool |
Logical boolean. Used for state validation (e.g., in a HandlerState machine). |
std::string |
Dynamically sized character sequences. Handle with care on devices with very limited RAM to prevent heap fragmentation. |
struct / class |
User-defined types acting as blueprints for your data models. |
3. Memory Management: Stack vs. Heap
At an architectural level, deciding where to place data profoundly impacts system performance and stability.
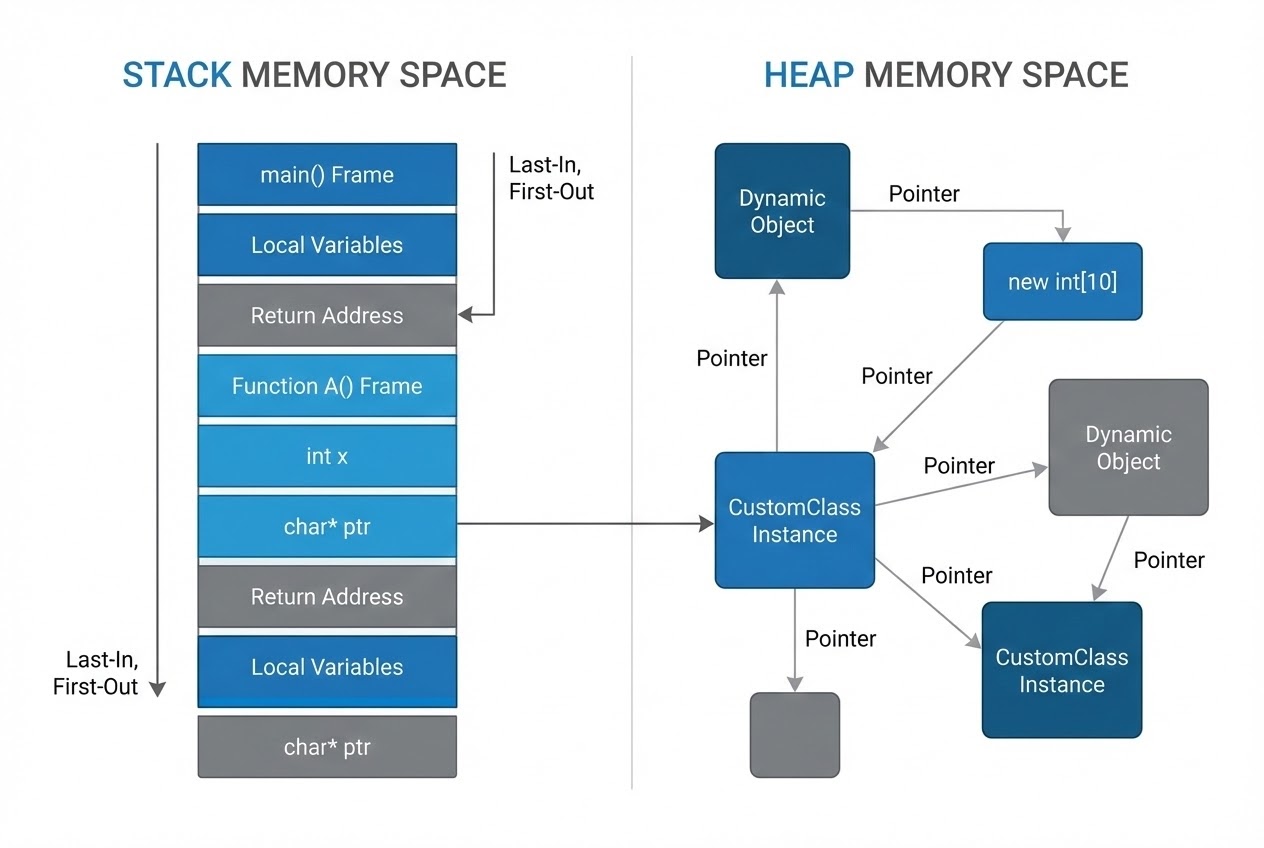
- Stack (Automatic Storage):
- Used to store local variables, like those declared inside a quick compute function.
- Pros: Extremely fast operation (LIFO structure) and zero manual memory management overhead. Memory is reclaimed automatically upon scope exit.
- Cons: Very limited space (especially on microcontrollers like ESP32 where task stacks are specifically sized). Data vanishes immediately when the function returns.
- Heap (Dynamic Storage):
- Allocated via the
newkeyword (e.g.,X* x = new X;or instantiating a new node in a lock-free queue). - Pros: Data persists as long as you need it. It is the only place suitable for large objects, massive ML buffers, or complex linked structures.
- Cons: If mismanaged, it leads to memory leaks or dangling pointers. Fragmentation can also crash an RTOS over time.
- Allocated via the
4. Pointers and References
This is the mechanism C++ uses for raw, direct control over memory addresses.
- Pointer (
*): A variable that holds a memory address. For example,X* ppoints to an object of typeXliving in the Heap. - Reference (
&): Creating an alias for a pre-existing variable. For instance, usingstd::ref(data)when passing values into a concurrent thread to avoid massive, performance-killing memory copies.
[WARNING] Dangling Pointers & Race Conditions: In advanced module designs (like Lock-free Data Structures), a frequent nightmare involves one thread deleting a data node while another thread is simultaneously trying to read from that exact pointer. Managing the lifecycle of pointers in concurrent systems requires extreme architectural precision.
5. Manual Memory Management: new and delete
When you step into the Heap, you assume absolute responsibility for that object’s lifecycle:
- Allocation: Use
newto grab memory and invoke the Constructor. - Utilization: Manipulate the data via your Pointer.
- Deallocation: You must invoke
deleteto return the memory to the system. Forgetting this equals a Memory Leak.
Practical Challenge: In lock-free system design, deleting a node immediately after popping it from a queue can cause fatal crashes if another thread is looking at it (Dangling Pointer). Engineers often rely on advanced techniques like Hazard Pointers or strict Reference Counting to guarantee no one is touching the pointer before bringing down the delete hammer.
6. Introduction to Smart Pointers
To mitigate human error, Modern C++ heavily pushes the “Ownership Model” utilizing Smart Pointers, which leverage RAII (Resource Acquisition Is Initialization) to automate memory recovery.
std::unique_ptr(Exclusive Ownership):- Declares sole ownership of a resource.
- When the
unique_ptrdrops out of scope, it automatically callsdeletefor you. Excellent forfunction_wrapperpatterns or managing internal nodes within athreadsafe_queue.
std::shared_ptr(Shared Ownership):- Employs a Reference Counting system to track how many entities own the resource.
- The raw resource is only destroyed when the very last owner goes out of scope.
[NOTE] Technical Warning: Even though
std::shared_ptroffers great safety nets, in high-performance or hard-real-time environments (like lock-free interrupts on an MCU), you must be aware that its control block operations might not be lock-free depending on the platform compiler, and the atomic reference counting does incur slight overhead. Software architects must always weigh convenience against raw performance requirements.
Conclusion
Mastering C++ memory management transforms you from someone who writes code to someone who engineers robust systems. Whether you’re wrangling tensors for Edge AI, building high-speed concurrent web servers, or calculating complex geometric matrices, appreciating the delicate balance between the Stack, the Heap, Pointers, and predictable lifecycles is the key to creating software that never crashes in the field.
References & Further Reading
- Anthony Williams - C++ Concurrency in Action
- Kirill Kolodiazhnyi - Hands-On Machine Learning with C++
- Daniel Sunday PhD - Practical Geometry Algorithms with C++ Code