Loop Unrolling: Shattering Loop Execution, Bleeding Maximum Speed Through the Art of 'Code Unfurling'

Introduction: The Hidden Latency of Repetition
Greetings, elite engineers and hardcore developers aggressively defending the www.123microcontroller.com grid! The dark-eyed engineer has securely logged back into the terminal. Today, we violently tear into a legendary, absolute heavy-artillery Optimization doctrine classified globally as Loop Unrolling (Code Unfurling)!
Any operative actively writing C code is intimately familiar deploying standard execution loops like for or while forcefully repeating sequential payloads. However, buried deep inside the bare-metal hardware silicon, executing a loop virtually always violently triggers a massive “Hidden Latency Overhead”! Imagine a physical operation where you are ordered to manually pack 100 heavy tactical crates. If you successfully pack exactly 1 crate, but then MUST stop, completely turn around, and physically check off a massive verification list 1 single time (Evaluating the Loop Condition)… successfully packing all 100 crates will bleed horrific amounts of time simply turning around! But what if we aggressively rewrite the protocol? What if you violently pack 4 crates sequentially in hyper-speed, and then turn around exactly 1 time striking the checklist? The operation finishes devastatingly faster! This is the exact brutal, mechanical logic driving Loop Unrolling from the perspective of both the Engineer and the Compiler Engine! Today, we rip open the tactical manuals dissecting exactly how grandmaster sources deploy this mechanism operating inside the massive overarching Optimization theater. Secure your pipelines, let’s unfurl!
Core Theory Autopsy: The Mechanism and Raw Power of Loop Unrolling
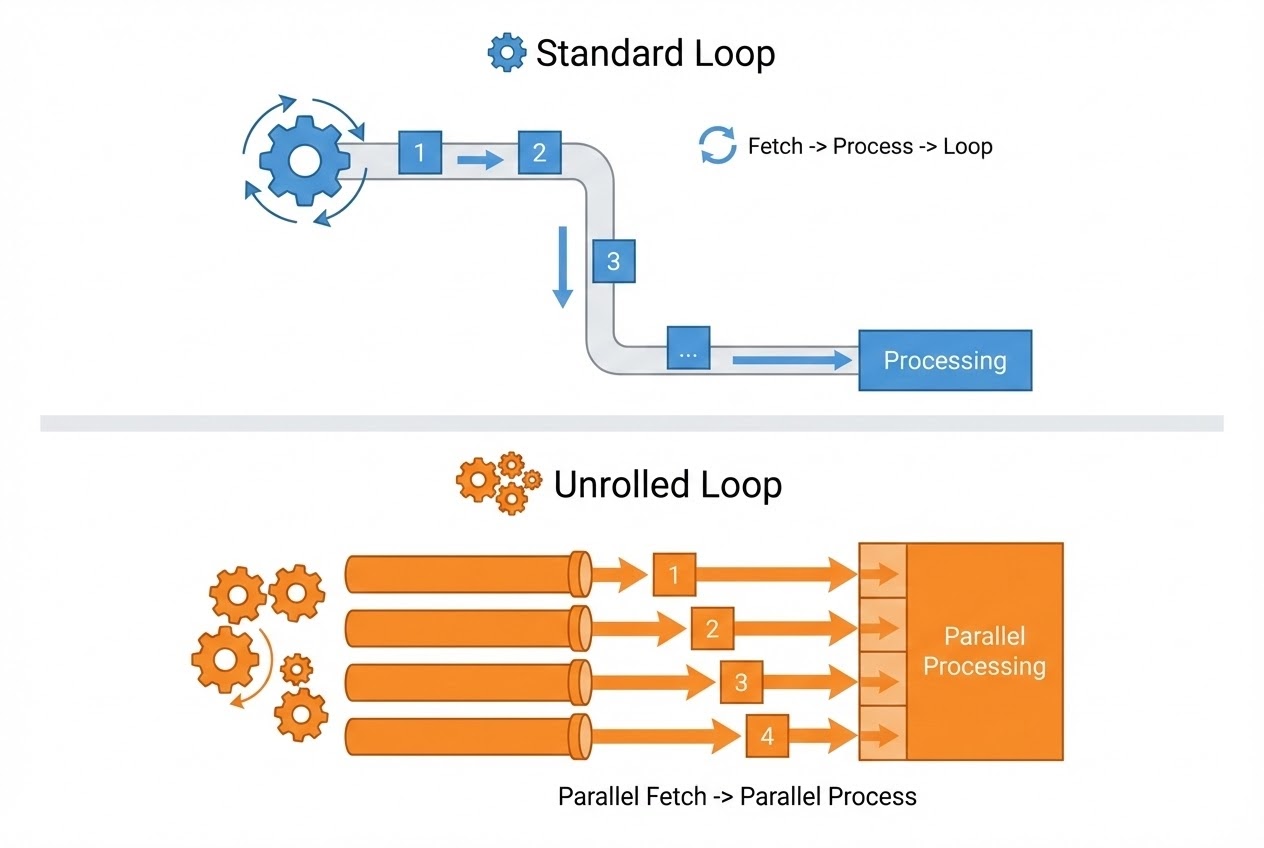
Operating deep within the heavily fortified Compiler Optimization theater, Loop Unrolling operates as an aggressive surgical mutation of the loop architecture. Its singular, violent objective is utterly annihilating wasted execution cycles (Loop Control Overhead) and brutally extracting the absolute maximum theoretical performance ceiling from the CPU. Memorize these heavy tactical impacts:
- 1. Obliterating Loop Overhead: Every single microsecond a loop successfully completes 1 cycle (Iteration), the CPU is violently forced to execute 3 absolute mandatory operations: 1) Incrementing the tracking variable (Increment), 2) Violently interrogating the termination logic (Condition Evaluation), and 3) Physically jumping the execution thread back to the starting coordinate (Branch Instruction). Executing Loop Unrolling literally “Clones and splices” the execution payload, violently slapping multiple continuous copies directly inside a single loop cycle! This aggressively forces the target CPU to process massive amounts of primary execution payloads while drastically bleeding the frequency it wastes interrogating conditions or violently jumping!
- 2. Forcing Instruction-Level Parallelism (ILP): Beyond simply bleeding the overhead latency, violently unfurling loops actively unlocks massive tactical opportunities forcing modern CPUs operating heavy Pipeline or Superscalar architectures to aggressively snatch multiple, completely unrelated execution commands (Independent instructions) and process them simultaneously, executing absolute parallel hardware supremacy (Instruction-Level Parallelism)!
- 3. Eradicating Branch Misprediction Casualties: Jumping coordinates (Branching) represents an absolute devastating nightmare terrorizing modern CPU Pipelines! If the CPU blindly hallucinates guessing the wrong jump trajectory, it is violently forced to completely flush and purge the entire massive pipeline architecture (Pipeline Flush)! Aggressively minimizing the raw frequency the CPU is forced to interrogate the loop directly minimizes the catastrophic risk of suffering severe Branch Misprediction penalties!
- 4. Synergizing with Vectorization (SIMD): Incredibly often, the Compiler aggressively weaponizes Loop Unrolling acting as the primary gateway authorizing heavy Vectorization deployments (e.g., triggering massive SSE/AVX hardware instructions, or single-click massive array bombardments). This unlocks the terrifying capability to violently extract multiple data bytes ripping them from an Array and mathematically calculating them simultaneously in a single explosive cycle!
- 5. The Time-Space Tactical Trade-off: Every weapon holds a counter-recoil! Aggressively unfurling loops deliberately cloning execution logic identically guarantees triggering massive “Program Binary Expansion (Code Bloat)”! Operating deep inside the Embedded trench possessing horrific Flash Memory restrictions, operatives MUST brutally calculate if the massive acceleration acquired actually justifies the total permanent sacrifice of precious ROM real estate!
Firing Live Code Rounds: Unfurling the Execution Track
Let us visually investigate a highly basic, manually executed Loop Unrolling operation. Assume we are commanded to aggressively copy a massive sensor data payload streaming from one storage Array directly into a secondary Array. If our intel absolutely guarantees the total data payload divides perfectly by a multiple of 4, we can violently rewrite the C architecture unlocking massive acceleration:
#include <stdint.h>
#define DATA_SIZE 100
/*
* Tactical Protocol 1: The Standard Sequential Loop (Normal Loop)
* The CPU is violently forced interrogating the 'i < DATA_SIZE' condition and executing 'i++' exactly 100 excruciating times!
*/
void copy_data_normal(uint32_t *dest, const uint32_t *src) {
for (uint32_t i = 0; i < DATA_SIZE; ++i) {
dest[i] = src[i];
}
}
/*
* Tactical Protocol 2: Loop Unrolling (Violently unfurling 4 sequential commands)
* The CPU will aggressively interrogate the condition and execute 'i += 4' strictly 25 times!
* Successfully annihilating Loop Overhead latency by a massive 75%!
*/
void copy_data_unrolled(uint32_t *dest, const uint32_t *src) {
/* Hardcore Intel absolutely guarantees DATA_SIZE perfectly mathematically divides by 4 */
for (uint32_t i = 0; i < DATA_SIZE; i += 4) {
dest[i] = src[i];
dest[i + 1] = src[i + 1];
dest[i + 2] = src[i + 2];
dest[i + 3] = src[i + 3];
}
}
Proximity Defcons: Heavy Best Practices & Fatal Pitfalls
While Loop Unrolling appears incredibly devastating, elite software engineering grimoires strictly issue heavy, terminal warnings regarding catastrophic pitfalls:
- Absolutely Trust the Compiler Engine: Operating in the modern era, super-intelligent Compilers like GCC are terrifyingly advanced! It possesses the capability to heavily aggressively unroll loops entirely autonomously if the operative authorizes heavy Optimization Flags (e.g.,
-O2,-O3, or-funroll-loops). Violently forcing manual unfurling (Manual unrolling) virtually always mutates the architecture into an illegible nightmare (Unreadable), and frequently, the Compiler executes the unrolling infinitely better than a human ever could! The strict exception: ONLY execute manual unrolls if you possess highly classified, absolute “specific hardware intelligence” that the Compiler remains blind to! - Beware the Code Bloat Cache Detonation (Instruction Cache Miss): If an operative aggressively unrolls a loop already securing massive physical magnitude, violently stretching it larger until it entirely eclipses and overflows the CPU’s physical Instruction Cache… this triggers absolute disaster! The CPU is violently forced repeatedly destroying cycles constantly reloading executing code dragging it from the slow Main Memory (Cache thrashing). This catastrophic blunder will force the program to execute significantly “SLOWER” than a basic standard loop!
- The Misaligned Remainder Catastrophe: Deployed in live combat, raw data payloads absolutely virtually never perfectly divide cleanly by 4 or 8 (e.g., intercepting exactly 103 data variables). Consequently, executing Manual Unrolling absolutely demands the operative violently forge a highly specialized “clean-up” code block tailing the primary loop strictly designed to process the remaining “Fragment Data (Remainder)”. This violently increases architectural complexity and massively amplifies the probability triggering explosive bugs (e.g., Catastrophic Array Out of Bounds Memory Segmentation Faults)!
- Duff’s Device (The Ancient Dark Art): Operating in archaic timelines, a hyper-hardcore C coding trick designated “Duff’s Device” was violently deployed! It aggressively smashed a bizarre
switchstatement violently intersecting directly over awhileloop architecture executing heavy Loop Unrolling while simultaneously obliterating the irregular remainder data purely in one chaotic strike! While historically considered absolute God-Tier intelligence, it violently mutates the architecture into incredibly hostile, unreadable spaghetti (Obfuscated)! Global grandmasters firmly advise permanently abandoning this hostile tactical maneuver, commanding operatives to surrender this specific heavy execution entirely back onto the Compiler engine!
Conclusion
Loop Unrolling represents the absolute primal, legacy art of extreme speed extraction, decisively proving the absolute golden law: “Shorter source code does NOT universally guarantee faster physical execution!” It serves as the absolute definitive, textbook manifestation defining the Time-Space Trade-off paradigm! Elite Embedded Operations engineers MUST absolutely calculate and deploy this strike with terrifying precision to aggressively extract maximum heavy performance violently ripping it from the CPU and internal Pipeline architecture!
If any operatives operating on the server are obsessively interested executing live fire tests writing code and deploying heavy scanning tools like Compiler Explorer, or visually tearing open the raw .lst (Assembly List) logs interrogating whether the GCC compiler covertly executed an unroll… drop a flare actively sharing the Assembly Code snapshots straight onto our active combat grid at www.123microcontroller.com! Maintain heavy shields, Happy Hardcore Coding to absolutely every operative!