Algorithm Choice & Big O Notation: The Ultimate Optimization Core, Infinitely More Lethal Than Low-Level Code Hacking!

Introduction: The True Origin of Extreme Performance
Greetings, elite engineers and hardcore developers aggressively defending the www.123microcontroller.com grid! The dark-eyed engineer has securely logged back into the terminal. Whenever operatives broadcast the term “Optimization (Extreme Performance Output)” inside the brutal trenches of Embedded Systems or System Programming, rookies immediately hallucinate writing bizarre, twisted Bitwise Operations, aggressively injecting Inline Assembly, or desperately attempting to violently squeeze maximum efficiency from a single microcontroller Register.
But listen closely, operatives: The absolute highest-tier engineering grandmasters globally universally agree that the most critical, absolutely violently impactful Optimization always firmly initiates from executing the correct “Algorithm Choice”! Endlessly bleeding out performing microscopic adjustments (Micro-optimization) on bare-metal code is utterly, completely useless if your foundational architectural framework or problem-solving logic is fatally flawed from the very first microsecond!
Today, we are aggressively deploying the heavy metric officially classified as Big O Notation, utilizing it as the ultimate diagnostic radar measuring exactly how brutally your CPU is bleeding. Let’s breach the optimization core and expose its massive impact across the broader architectural grid!
Core Theory Autopsy: Why is Algorithm Choice the Absolute Foundation of Optimization?
Inside the software combat zone, executing Optimization operates as the brutal, relentless campaign to violently suppress and minimize critical resource consumption (e.g., Execution Time latency or physical Memory footprint). Comprehending and deploying the absolute perfectly matched algorithm operates executing a massive “Architectural (Macro-optimization)” strike, which perpetually, brutally outclasses and annihilates microscopic code-level tweaks. Memorize these heavy tactical principles:
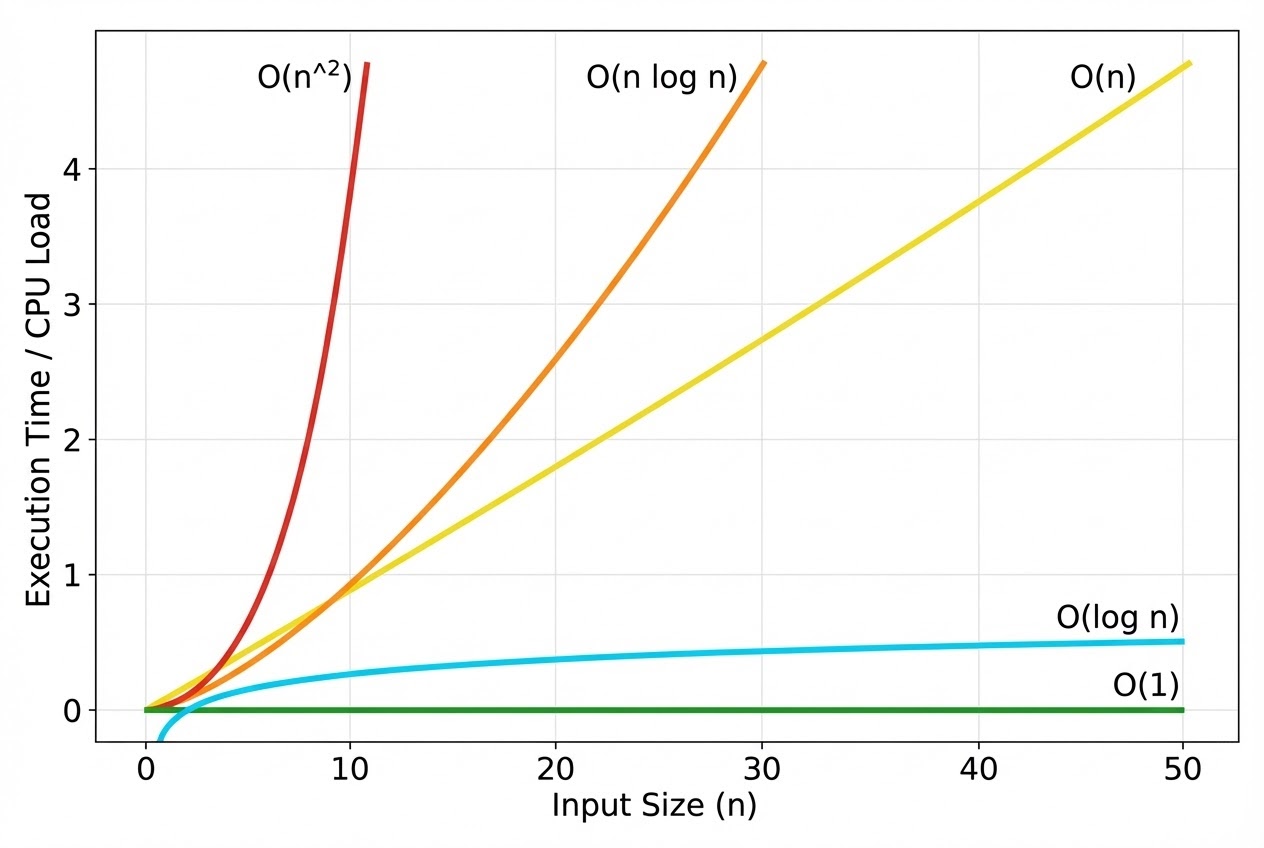
- 1. What the Hell is Big O Notation? Big O, or $O(n)$, operates as the heavy mathematical classification scanner specifically deployed determining the “Absolute Upper Bound” or the “Maximum Catastrophic Worst-Case Scenario” measuring exactly how an algorithm physically degrades when the raw data payload (Input size, or $n$) violently scales and expands! It acts as an early-warning radar, exposing exactly how drastically your CPU engine will hemorrhage and overheat as massive data streams are violently shoved into the microcontroller.
- 2. Purging the Constant Factors (Ignoring Constants): The absolute Iron Law of Big O demands we totally, ruthlessly terminate tracking all “Constant factors”! For example, observe an algorithm executing burning $3n^2 + 10n + 10$ cycles. When $n$ violently scales reaching massive proportions (e.g., slamming a million explosive sensor data points), the absolutely dominant, most lethal thermal metric crushing the system is strictly the $n^2$ singularity! Therefore, we brutally classify this algorithm locked at a highly dangerous $O(n^2)$ threat level. Shaving down constant factors (e.g., bleeding to reduce $3n^2$ down to $1n^2$) represents the absolute maximum victory achievable via low-level Micro-optimization. However, violently shattering an $O(n^2)$ architecture and completely ripping replacing it forging an $O(n)$ engine? That is the absolute, god-tier dark magic of changing the Algorithm!
- 3. The Heavy Complexity Classes (Execution Threat Levels):
- $O(1)$ Constant Time: God-Tier! Regardless of how massive the alien data payload scales, the execution time remains absolutely flatlined! (e.g., Extracting data striking an Array via direct Index, or deploying a heavy Lookup Table).
- $O(\log n)$ Logarithmic Time: Hyper-lethal speed! It violently slaughters the targeted data pool, completely cutting the search space entirely in half every single execution cycle! (e.g., Binary Search).
- $O(n)$ Linear Time: The thermal load scales directly parallel matching the raw data count. (e.g., Brute-force scanning an Array sequentially from point zero to the terminal sector, Linear Search).
- $O(n \log n)$: The standard operating threat level for highly weaponized, efficient sorting algorithms (e.g., Merge Sort, Quick Sort).
- $O(n^2)$ Quadratic Time: A catastrophic thermal runaway! As data scales, execution time violently explodes! Virtually always triggered executing fatal Nested Loops! (e.g., Bubble Sort, Selection Sort).
- 4. The Time-Space Tactical Trade-off: Operating deep inside the Embedded trench, our silicon platforms suffer massive constraints restricting both Speed (Time latency) and physical Memory footprint (Space capacity). Frequently, elite operatives can aggressively force code executing drastically faster by actively authorizing “Massive RAM Consumption”! For instance, willingly sacrificing heavy chunks of RAM forging massive Arrays caching pre-computed explosive data (Lookup Tables). This grants the system authority executing readings striking at $O(1)$ speeds, entirely preventing the CPU from bleeding out running live mathematical equations every single microsecond!
Firing Live Code Rounds: Linear Search vs Binary Search
Let us visually investigate an elite data extraction operation proving exactly why matching the algorithm dictates absolute survival. Assume we possess an Array heavily loaded securing 1,000 sequentially sorted data points. If we deploy a brute-force scanning sweep (Linear Search), hitting the absolute worst-case catastrophe, the CPU is forced violently looping 1,000 times ($O(n)$)! However, if we immediately upgrade deploying the highly weaponized Binary Search algorithm, the absolute maximum maximum extraction time plummets to roughly 10 execution loops ($O(\log n)$)! This exposes the raw, terrifying power generated strictly executing an Algorithm Change!
#include <stdio.h>
#include <stdint.h>
#include <stdbool.h>
/*
* 1. The Linear Search Engine: O(n) Threat Level
* Tactical Advantage: Extremely simple to forged; absolutely zero requirement pre-sorting the data payload.
* Fatal Flaw: Horrific latency if the array payload expands. (A million data points directly translates to potentially a million execution loops!)
*/
int32_t linear_search(const int32_t arr[], uint32_t size, int32_t target) {
for (uint32_t i = 0; i < size; ++i) {
if (arr[i] == target) {
return i; /* Target acquired! Instantly returning physical Index */
}
}
return -1; /* Target MIA / Not Found */
}
/*
* 2. The Binary Search Engine: O(log n) Threat Level
* Strict Prerequisite Directive: The Array payload MUST absolutely be "Sorted" chronologically or sequentially prior to execution!
* Tactical Superiority: Absolute Hyper-Speed! Hunting a target within a million data points requires maximally 20 execution loops!
*/
int32_t binary_search(const int32_t arr[], uint32_t size, int32_t target) {
int32_t left = 0;
int32_t right = size - 1;
while (left <= right) {
/* Calculating the absolute mathematical center (Divide by 2) aggressively halving the combat search grid every cycle */
int32_t mid = left + (right - left) / 2;
if (arr[mid] == target) {
return mid; /* Target acquired! */
}
if (arr[mid] < target) {
left = mid + 1; /* Target location isolated moving into the right flank */
} else {
right = mid - 1; /* Target location isolated moving into the left flank */
}
}
return -1; /* Target MIA / Not Found */
}
int main(void) {
int32_t sorted_sensor_data[] = {10, 25, 32, 45, 50, 68, 72, 85, 90, 100};
uint32_t data_size = sizeof(sorted_sensor_data) / sizeof(sorted_sensor_data);
int32_t target_val = 68;
/* Executing the superior Algorithm choice instantly dominates over any micro-level optimization attempt imaginable! */
int32_t index = binary_search(sorted_sensor_data, data_size, target_val);
if (index != -1) {
printf("Critical target tracking acquired %d at exact index %d\n", target_val, index);
} else {
printf("Target completely evaded detection. Not found.\n");
}
return 0;
}
Proximity Defcons: Heavy Best Practices & Fatal Pitfalls
While aggressively picking algorithms using Big O is mandatory, there are massive landmines that constantly obliterate overzealous rookies. International software engineering command standards explicitly enforce these survival protocols:
- Beware the Demon of Premature Optimization (The Root of All Evil): This is the legendary, immortal combat quote from Grandmaster Donald Knuth. Frantically aggressively attempting to heavily mutate your code rendering it totally unreadable, prioritizing saving tiny microscopic fractions of time far too early in the development cycle, virtually always breeds massive, undetected, catastrophic bugs! Operatives MUST fiercely prioritize forging highly legible, mathematically correct code first! Following that, “Aggressively deploy Heavy Measurement Tools (Profilers/Data-loggers)” precisely tracking down exactly which sector is literally choking causing the thermal bottleneck! Then—and exactly only then—execute surgical Optimization targeting that specific zone! Never blindly guess!
- The Small Input Trap ($Small n$ Ambush): Affirmative; a mathematically pure $O(n \log n)$ algorithm brutally dominates any $O(n^2)$ engine whenever the data payloads scales into thousands or millions. But if your specific project architecture guarantees operating holding a tiny payload maximally maintaining 5-10 values… deploying a raw, basic $O(n^2)$ algorithm or a simple Linear Search $O(n)$ will actually execute significantly faster! Because the internal architecture is so bare-bones simple (carrying an incredibly low Constant factor), it easily outruns the massive heavy setup latency required booting a highly complex alien theoretical algorithm!
- Absolutely Never Reinvent the Wheel: If your combat zone demands deploying a highly complex algorithm commanding absolute surgical optimization—such as executing an FFT (Fast Fourier Transform), or heavy mathematical sorting—always, strictly, without fail deploy the heavy Standard Libraries authorized by the OS, or the bare-metal DSP Libraries provided directly by the silicon manufacturer! Their elite engineers have heavily coded and fused those algorithms executing directly hardware-accelerated, squeezing performance that you will absolutely never achieve coding raw manually!
Conclusion
Stepping back commanding the wide overarching perspective of System Optimization, executing the ultimate “Algorithm Choice” heavily paired analyzing raw metrics utilizing Big O Notation represents the absolute primal, most critical navigational beacon in existence! Instead of bleeding for days aggressively tweaking twisted naked Assembly Language hoping to shave off a single cycle, simply structurally pivoting your entire architecture from a lagging Linked List straight into a highly volatile Hash Table… or surgically neutralizing an exploding $O(n^2)$ loop into a clean $O(n \log n)$ cycle… exactly this maneuver guarantees injecting massive, colossal acceleration directly into your Embedded infrastructure completely dwarfing any other effort imaginable!
If any operatives operating on the server are obsessively interested exploring bizarre deployments aggressively cramming twisted Data Structures into heavily restricted bleeding RAM microcontrollers, or if anyone has horrifically accidentally deployed an infinite loop permanently hanging their silicon array (I have absolutely triggered that specific catastrophe myself! 😅), drop a flare actively bleeding sharing the logistics straight onto our active combat grid at www.123microcontroller.com! Maintain heavy shields, Happy Hardcore Coding to absolutely every operative!